
Hitting the Memory Wall Implications of the Obvious
论文笔记
历史
内存墙是指处理器在处理大量数据时,往往需要等待来自比较慢的 RAM 内存的数据。 因此,数据密集型算法每秒运行的计算量比处理器理论上的计算量要少。这是一个持续存在的问题,而且几十年来它变得越来越糟,因为与处理器速度相比,内存速度的进步本质上是较慢的。它在 1994 年的论文 Hitting the Memory Wall: Implications of the Obvious 中首次被描述。
描述一般情况下内存访问时间的公式如下:
其中分别表示cache访问时间、DRAM访问时间、以及cache命中率。
随着技术的不断发展(处理器速度于存储设备的访问速度),平均访存时间将如何变化呢?我们不妨假设cache的速度与处理器速度相同并且增长速度相同,很多处理器的片上cache已经达到这一性能,即。此外我们假设cache性能完美,即cache不会发生碰撞以及容量缺失,仅有的访存缺失是程序中必不可少的访存缺失,即是访问以往从未被引用过的内存地址的概率。
虽然很小,但是仍然大于0。因此当和相差越来越大时,平均内存访问时间也将上涨,系统的性能将下降,实际上系统性能将遇到瓶颈。
在大多数程序中有20-40%的指令会访问memory,我们取最低概率20%,那么大约每5条指令中会有一条指令访问memory。因为随着处理器速度的提升,运行五条指令的时间将逐渐减小,当即内存访问时间超过5条指令执行时间的时候,系统的性能将取决于内存的访问速度。因为处理器性能的提升并不能让内存访问的速度变快。单独考虑处理器执行这五条指令,大部分时间都在等内存访问。此时再提升处理器的速度并不会提升执行程序的时间,系统的性能提升遇到了一堵墙。
发生时机
在处理任何类型的数据时都可以观察到这种现象,只要数据量足够大。 它可以发生在当今任何类型的计算机中,例如 超级计算机、台式计算机、笔记本电脑、智能手机或平板电脑。 因为这是一个硬件绑定问题,所以更改编程语言对其没有影响。
对于需要重复处理的少量数据,可以充分利用处理器的性能,因为数据可以完全保存在处理器的寄存器中,也可以保存在处理器芯片上的高速缓存中。 当存储在那里时,不需要从较慢的 RAM 加载。 但是当数据量更大并且不再适合寄存器或处理器缓存时,需要从 RAM 加载数据。 这很慢 - 与寄存器和处理器缓存相比 - 它会减慢计算速度。
趋势预测
论文 Hitting the Memory Wall: Implications of the Obvious 中对内存墙的发展趋势进行了预测。
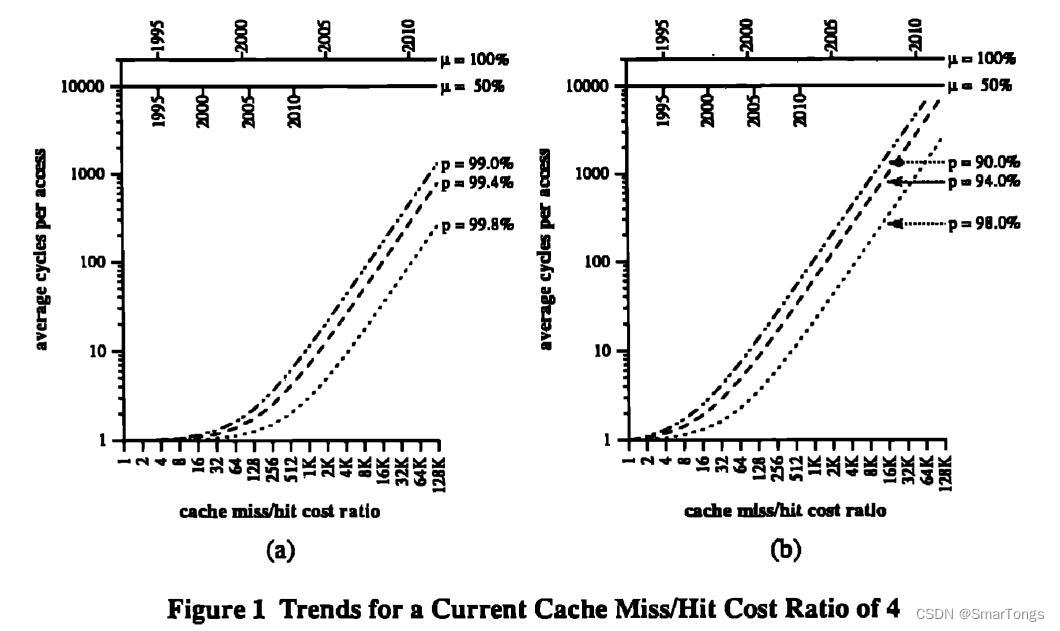
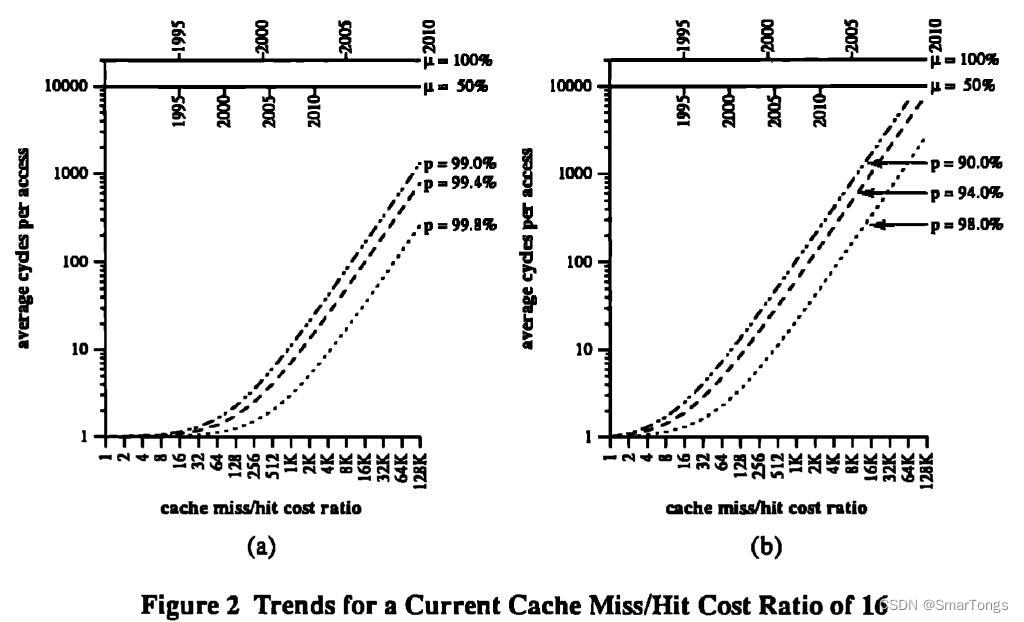
图1、图2探讨了各种可能性,假设DRAM的性能每年增长7%。横坐标是CPU与DRAM的性能比。最上方的横线表明,在不同的处理器增速下,CPU/DRAM性能比例的发展时间线。图1中假设cache缺失时的访存时间为命中时的四倍。左图的缺失率小于1%,右图的缺失率更加真实,为2-10%。图1图2中的缺失/命中比率不同。
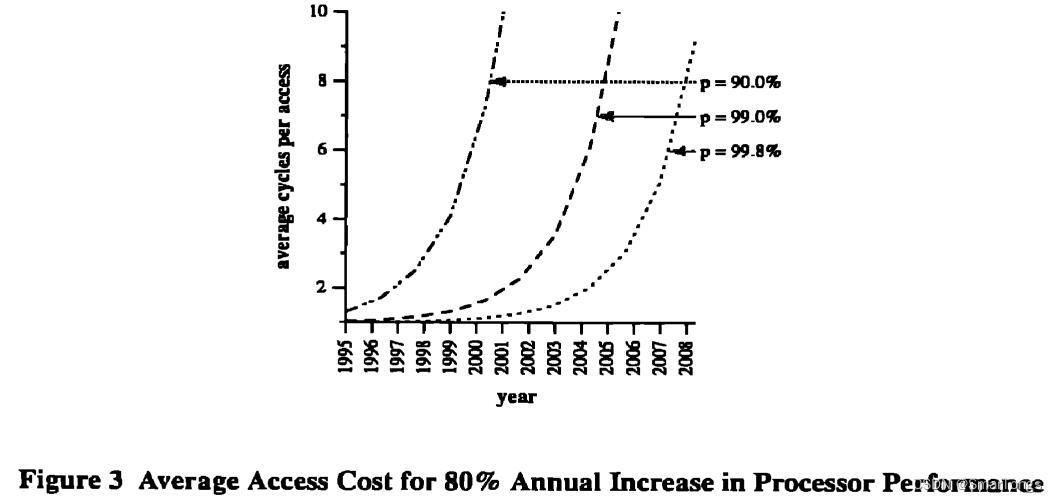
图3中假设处理器每年的发展速度为80%,保守估计cache缺失/命中比为4,在cache命中率99.8%的情况下2007年左右平均访存时间将达到5个cycle。如果cache命中率为90.0%,这一天将更早到来。
优化方法
最方便的解决方法就是研发一种速度与处理器匹配得存储技术,但是作者在论文书写时声称尚未发现此种技术。作者将目光转向了架构解决方法并进行了以下探讨。
- 能否避免cache访存丢失,如果我们无法提升DRAM性能,能否使cache的命中率达到100%。但是采取何种初始化写入以及更新策略使得cache命中率达到100%很难想象。
- 是否有新的方式能够用computation换storage,或者说,我们能否用space换speed。
- 古老的IBM 650、Burroughs 205等机器使用磁鼓作为主要存储设备并设计了巧妙的策略来降低旋转延迟,能够启发后续发展?
实验
测试程序
通过以下程序测试memory wall对程序性能的影响,测试环境如下:
| 项目 | 版本 |
|---|---|
| CPU | Intel(R) Core(TM) i5-8300H CPU @ 2.30GHz |
| Operating system | Ubuntu 16.04 |
| Environment | java 1.8 64bits |
1 | import java.lang.Math; |
上述程序申请一个元素类型为float的数组,java中一个float类型的变量占用4个字节(Byte)。通过不断改变申请的float类型数组大小来模拟申请不同内存大小情况下程序的性能。衡量指标采用程序单位时间执行的操作次数表示。profile函数返回对申请数组进行特定操作花费的时间,单位为纳秒。main函数返回运行profile函数,取用时最小来表示该申请数组大小下的最优性能。最后打印每纳秒程序执行的操作次数。
结果观察以及解释
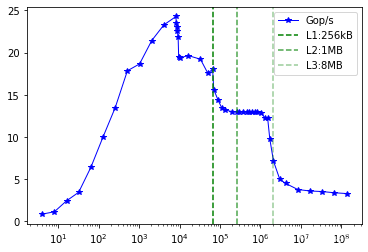
- 现象:上图为实验结果,横坐标为申请的数组长度,纵坐标是程序每秒执行的操作次数。图中有几组不同的区域,每一个区域都有不同的特点。折线图中起始点处的数组为,16 Bytes,此时系统的性能为0.851 Gop/s。在这之后,随着申请的数组大小增加,程序的每秒进行的操作数量整体呈现上升趋势。当申请大小为32KB的时候达到最大24.28Gop/s。随后性能急剧下降,大概可以观察到有三次下降,每次下降之后会有一段相对平缓的性能区域。
- 解释:-
- CPU最高只有2.30GHz但是最高性能达到了24.28Gop/s,这是因为java中的 Auto Vectorization自动向量化。
- 第一段的增长是java对于处理可变长数组时进行了优化。图表开头的斜率增加是处理可变数组大小所需的开销的结果。 由于需要处理各种数组大小的能力,如果在编译时知道数组大小,则 profile(…) 方法中的代码无法进行尽可能多的优化。 随着数组大小的增加,这种开销在整个处理负载中的比例越来越小。 出于这个原因,增加数组大小会使这段代码更有效率。
- 自然地,Java 的 JIT 编译器产生的优化质量会对效率产生巨大影响。 这些优化通常是草率的,没有使用 CPU 指令集的全部功能。 这以及无法为动态数组大小生成最优化的代码会导致性能跳跃。
- 按照缓存理论,后续的三个性能下降点应该和L1、L2、L3三级缓存的大小相吻合,但是前两次下降却提前到来,第三次下降的转折点与L3级缓存大体吻合。这里猜测可能是使用了虚拟机等其软件,CPU的缓存被其他任务有所占用。
附录
 微信
微信 支付宝
支付宝