
cmu15-445-3 Data Storage
存储
我们将重点关注一个“面向磁盘”的DBMS体系结构,该体系结构假设数据库的主存储位置位于非易失性磁盘上。
在存储层次结构的顶部,您有最接近CPU的设备。这是最快的存储空间,但它也是最小和最昂贵的。远离CPU越远,存储设备的容量就越大,但离CPU也越远。这些设备的每GB值也会更便宜。
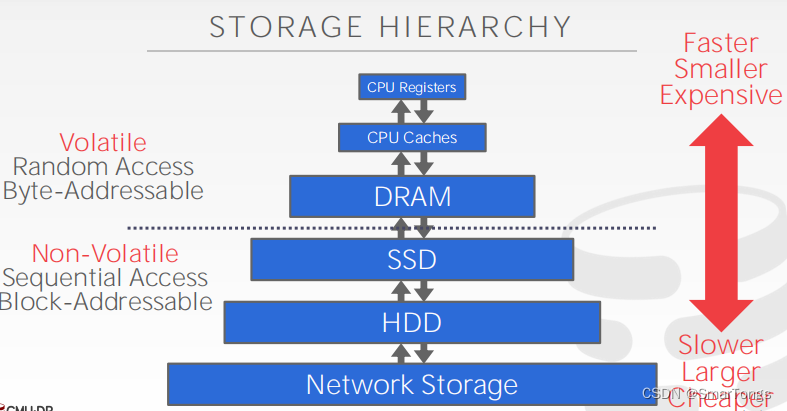
Volatile Devices:
- Volatile means that if you pull the power from the machine, then the data is lost.
- Volatile storage supports fast random access with byte-addressable locations. This means that the program can jump to any byte address and get the data that is there.
- For our purposes, we will always refer to this storage class as “memory”.
Non-Volatile Devices:
- Non-volatile means that the storage device does not need to be provided continuous power in order for the device to retain the bits that it is storing.
- It is also block/page addressable. This means that in order to read a value at a particular offset, the program first has to load the 4 KB page into memory that holds the value the program wants to read.
- Non-volatile storage is traditionally better at sequential access (reading multiple chunks of data at the same time).
- We will refer to this as “disk”. We will not make a (major) distinction between solid-state storage(SSD) or spinning hard drives (HDD).
还有一种新的存储设备即将问世,称为非易失性存储器(non-volatile memory)。这些设备被设计成最好的两个世界:几乎和DRAM一样快,但具有磁盘的持久性。
由于系统假定数据库存储在磁盘上,因此DBMS的组件负责确定如何从非易失性磁盘和易失性存储器中来回移动数据,因为系统不能直接在磁盘上操作数据。
我们将关注如何隐藏磁盘的延迟,而不是使用寄存器和缓存的优化,因为从磁盘获取数据非常慢。如果从L1缓存引用中读取数据需要半秒,那么从SSD中读取需要1.7天,从HDD中读取需要16.5周。
面向磁盘的DBMS概述
数据库均在磁盘上,数据库文件中的数据被组织成页面(page),第一个page是目录page。为了对数据进行操作,DBMS需要将数据加载到内存中,这一操作通过设置一个缓冲池,管理磁盘和内存之间数据的来回移动。DBMS还有一个可以执行查询的执行引擎。执行引擎向缓冲池申请特定的页面,缓冲池负责将该页面载入内存并为执行引擎分配一个指向内存中该页面的指针。当执行引擎对该内存地址进行操作时,缓冲池管理器确保需要的页面在这一位置。
DBMS vs OS
DBMS的一个高层次的设计目标是使得数据库能够使用的内存大小超过memory的大小。由于读写磁盘的成本高昂,因此必须仔细管理它。我们不希望从磁盘中读取数据时给系统中其他部分带来延迟,所以我们希望当系统等待从磁盘中取出数据时DBMS可以去处理其他的查询任务。
这一高层的设计目标有点类似于虚拟内存,虚拟内存具有较大的地址空间且支持操作系统从磁盘中加载页面。实现这种虚拟内存的一种方法是使用mmap在进程地址空间中映射文件的内容,这使得操作系统负责在磁盘和内存之间来回移动页面。不幸的是,这意味着如果mmap出现页面错误,这将阻止该进程。
- You never want to use mmap in your DBMS if you need to write.
- The DBMS (almost) always wants to control things itself and can do a better job at it since it knows more about the data being accessed and the queries being processed.
- The operating system is not your friend.
对于复杂场景下的多个写任务可以通过以下方式进行优化:
- madvise:告诉操作系统知道你什么时候计划阅读某些页面
- mlock:告诉操作系统不要将内存范围交换到磁盘
- msync:告诉操作系统将内存范围刷新到磁盘
尽管系统具有操作系统可以提供的功能,但让DBMS实现这些过程本身可以给它更好的控制和性能。
File Storage
一般DBMS将数据库作为文件存放在磁盘上,一些采用文件层次结构,一些使用单个文件(SQLite)。该操作系统并不知道这些文件的内容。只有DBMS知道如何解读它们的内容,因为它是以一种特定于DBMS的方式进行编码的。DBMS的存储管理器负责管理数据库的文件,其将文件表示为页面page的集合。它还可以跟踪已读取和写入页面的数据,以及页面中有多少空闲空间。
Database Pages
DBMS通过一个或多个固定大小的数据块(page)组织数据库。页面可以包含不同类型的数据(元组、索引等)。大多数系统不会在页面中混合这些类型。有些系统要求页面包含读取页面内容所需的信息。
每个页面都有一个唯一的标识符DBMS。如果数据库是单个文件,那么页面id可以只是文件的偏移量。大多数DBMS都有一个间接层,它将页面id映射到文件路径和偏移量。系统的上层将要求提供一个特定的页号,然后存储管理器将必须将该页号转换为一个文件和一个偏移量来找到该页面。
大多数DBMS使用固定大小的页面,以避免支持可变大小的页面所需的工程开销。例如,对于可变大小的页面,删除一个页面可能会在文件中创建一个漏洞,而DBMS无法轻松填充新页面。
DBMS中的页面有三个概念:
- Hardware page (usually 4 KB).
- OS page (4 KB).
- Database page (1-16 KB).
存储设备保证对硬件页面大小的原子写入。如果硬件页面为4KB,那么当系统试图将4KB写入磁盘时,要么写入所有4KB,要么不写入它们。这意味着,如果我们的数据库页面大于我们的硬件页面,DBMS将不得不采取额外的措施来确保数据安全写入,因为当系统崩溃时,程序可以通过将数据库页面写入磁盘。
Database Heap
不同的DBMS在管理磁盘文件中的页时采用不同的方法:
- Heap File Organization
- Sequential/Sorted File Organization
- Hashing File Organization
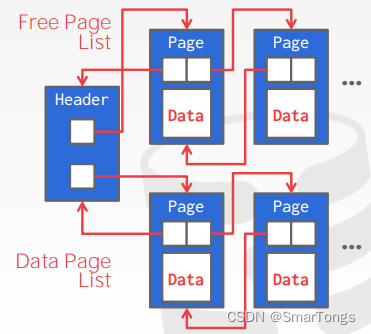
堆文件是页面的无序集合,其中元组以随机顺序存储。DBMS可以根据给定的page_id使用页面的链接列表或者页面目录在磁盘上定位页面。
Linked List:
头页面保存指向空闲页面和数据页面的指针。但是,如果DBMS正在寻找一个特定的页面,那么它必须对数据页面列表进行连续扫描,直到找到它正在查找的页面。
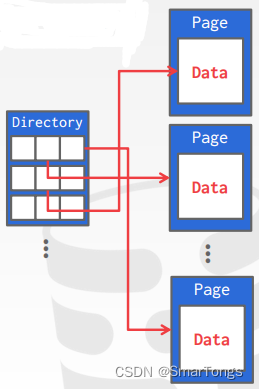
Page Directory:
DBMS维护一些特殊的页面,用来跟踪数据页面的位置以及每个页面上的空闲空间量。
Page Layout
每一个页面都包含了一个头,其中保存了页面内容的元数据。

Page Size
Checksum
DBMS Version
Transaction Visibility
Compression Information
- Some systems require pages to be self-contained (oracle)
关于如何在页面中存储元组,最简单的方法是Strawman Idea:记录页面中元组的数量并将新的元组添加至页面的末尾。但是当删除元组或者元组的长度不固定时存在缺陷。
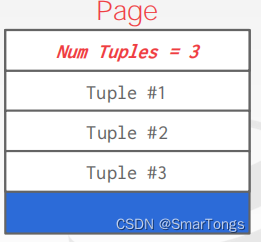
关于数据在页面中的存放方式主要有两种。
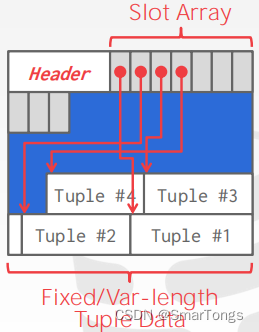
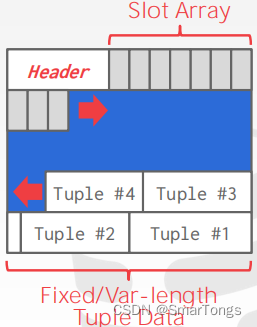
slotted-pages
- 页面将插槽映射到偏移量。目前在DBMS中最常用的方法。
- Header跟踪已使用的槽的数量以及最后使用的槽和一个槽阵列的起始位置的偏移量,它跟踪每个元组的起始位置。
- 要添加一个元组,插槽数组将从开始到端增长,而元组的数据将从端到开始增长。当插槽数组和元组数据满足时,该页面被认为是满的。
 |
 |
|---|---|
log-structured
不采用存储元组的方式,直接在page中存储日志记录。
将记录存储到修改数据库的文件(插入、更新、删除)。
如要读取记录,DBMS会向后扫描日志文件并“重新创建”元组。
快速写,可能读取较慢。
在仅附加存储上工作得很好,因为DBMS不能返回和更新数据。
- 为了避免长时间的读取,DBMS可以使用索引来允许它跳转到日志中的特定位置。它还可以定期压缩日志(如果它有一个元组,然后对其进行更新,它可以将其压缩到只插入更新后的元组)。压缩的问题是DBMS最终以写入放大(它一遍又一遍地重新包装相同的数据)。
 |
 |
|---|---|
Tuple Layout
一个元组本质上是一个字节序列。DBMS的工作是将这些字节解释为属性类型和值。
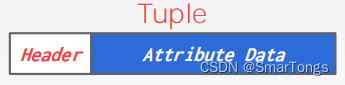
Tuple Header: 包含与该元组有关的元数据
- DBMS的并发控制协议的可见性信息(关于创建/修改该元组的事务的息)。
- 空值的位映射。
- 请注意,DBMS不需要在这里存储关于数据库模式的元数据。
Tuple Data: 各个属性的真实值
- 属性通常按照您在创建表时指定属性的顺序存储。
- 大多数DBMS不允许一个元组超过一个页面的大小。
Unique Identifier:元组的惟一标识
- 数据库中每一个元组都被分配了一个唯一标识
- 常见格式为:page_id+(offset or slot)
- 标识可能会动态变化,应用程序不能过度依赖
Denormalized Tuple Data:反正则化数据
如果有两个表是相关的,那么DBMS可以“预连接”它们,因此这些表最终会出现在同一页上。这使得读取速度更快,因为DBMS只需要加载一个页面,而不是两个单独的页面,但它使更新更加昂贵,因为DBMS为每个元组需要更多的空间。
Data Representation
元组的数据本质上只是字节数组。由DBMS知道如何解释这些字节来导出属性的值。数据表示方案是DBMS如何存储一个值的字节。主要类型可以存储在元组中:整数、可变精度数、固定点精度数、可变长度值和日期/时间。
Integers
- 大多数DBMS使用IEEE-754标准所指定的“本机”C/C++类型来存储整数。这些值是固定的长度;
- 例如:INTEGER, BIGINT, SMALLINT, TINYINT;
Variable Precision Numbers
- 使用IEEE-754标准指定的“本地”C/C++类型的不精确的、可变精度的数字类型。这些值也是固定的长度
- 可变精度数比任意精度数计算得更快,因为CPU可以直接在它们上执行指
- 例如: FLOAT, REAL
Fixed Point Precision Numbers
- 这些都是具有任意精度和规模的数字数据类型。它们通常以精确的、可变长度的二进制表示形式存储,而附加的元数据将告诉系统十进制应该在哪里。
- 当舍入错误不可接受时,将使用这些数据类型,但是DBMS会支付性能损失以获得这种精度。
- 例如:NUMERIC, DECIMAL
Variable Length Data
- 一个具有任意长度的字节数组。
- 有一个跟踪字符串长度的头,以便很容易跳转到下一个值。
- 大多数DBMS不允许元组超过单个页面的大小,因此它们通过在溢出页面上写入值,并使元组包含对该页面的引用来解决这个问题。
- 有些系统允许您将这些大值存储在外部文件中,然后元组将包含一个指向该文件的指针。例如,如果我们的数据库中存储了照片信息,那么我们就可以将照片存储在外部文件中,而不是让它们在DBMS中占用大量的空间。这样做的一个缺点是,DBMS无法操作该文件的内容
- 例如:VARCHAR, VARBINARY, TEXT, BLOB
Dates and Times
- 自从unix出现以来,通常都被表示为(微/毫)秒的数量
- 例如:TIME, DATE, TIMESTAMP
Workloads
OLTP: On-line Transaction Processing 在线事务处理
- Fast, short running operations
- Queries operate on single entity at a time
- More writes than reads
- Repetitive operations
- Usually the kind of application that people build first
- Example: User invocations of Amazon. They can add things to their cart, they can make purchases,but the actions only affect their account.
OLAP: On-line Analyitical Processing 在线分析处理
- Long running, more complex queries
- Reads large portions of the database
- Exploratory queries
- Deriving new data from data collected on the OLTP side
- Example: Compute the five most bought items over a one month period for these geographical locations
Storage Models
N-Ary Storage Model (NSM)
DBMS连续地存储单个元组的所有属性,因此NSM也被称为“行存储”。这种方法非常适合于OLTP工作负载,在那里,事务往往只操作单个实体并插入大量的工作负载。它是理想的,因为它只需要一次获取就可以获得单个元组的所有属性。
优点:
Fast inserts, updates, and deletes
Good for queries that need the entire tuple
缺点:
- Not good for scanning large portions of the table and/or a subset of the attributes. This is because it pollutes the buffer pool by fetching data that is not needed for processing the query
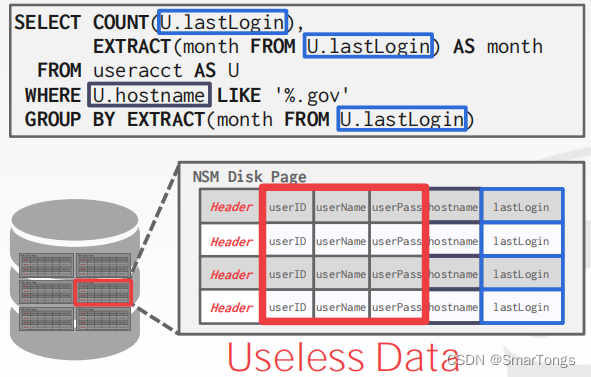
两种组织NSM数据库的方式:
Heap-Organized Tables: 堆组织表
元组存储在称为堆的块中,并且堆不一定定义顺序。
Index-Organized Tables:索引组织表
元组存储在主键索引本身中,但与聚集索引不同。
Decomposition Storage Model (DSM)
DBMS在一个数据块中连续存储所有元组的单个属性(列)。也被称为“列式存储”。这个模型非常适合于OLAP工作负载,在这些工作负载中,只读查询对表的属性子集执行大型扫描。
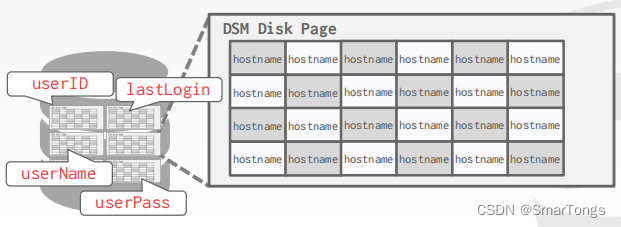
优点:
- 减少了在查询执行过程中浪费的工作量,因为DBMS只读取该查询所需的数据。
- 支持更好的压缩,因为相同属性的所有值都是连续存储的。
缺点:
- 由于元组被拆分/拼接,导致点查询、插入、更新和删除的速度较慢。
当我们使用列存储时,为了将元组放在一起,我们可以使用:
Fixed-length offsets:
首先,假设这些属性都是固定长度的。然后,当系统想要一个特定元组的属性时,它就知道如何跳转到文件中的那个位置。为了适应可变长度的字段,系统可以填充它们,使它们都是相同的长度,或者您可以使用一个固定大小的整数并将整数映射到值。
Embedded Tuple Ids:
对于列中的每个属性,都要使用其来存储元组id。系统还需要额外的信息来告诉它如何跳转到具有该id的每个属性。
大多数DBMS使用固定长度的偏移量。
**Row stores are usually better for OLTP, while column stores ar better for OLAP.** 微信
微信 支付宝
支付宝


