
cmu445-4 Buffer Pools
上一节描述了DBMS如何在磁盘的文件上描述数据库,这一节将描述DBMS如何管理其内存以及管理数据在磁盘上的来回移动。
这里总结一下两个概念:
Spatial Control:空间控制
- 将页面写入磁盘的哪个位置
- 其目标是使一起使用的页面在物理上尽可能接近
Temporal Control:时间控制
- 何时将页面读入内存,何时将其写入磁盘
- 其目标是最小化必须从磁盘读取数据时产生的延迟
Locks vs. Latches
在讨论DBMS如何保护其内部元素时,我们需要区分锁(lock)和锁存器(latch)。
Lock:
- 保护数据库的逻辑内容,如元组、表、数据库不受其他事务影响
- 事务处理期间一直持有
- 需要能够回滚更改
Latch:
- 保护DBMS内部数据结构的关键部分不受其他线程的影响
- 操作期间持有
- 不需要能够回滚更改
Buffer Pool
Buffer Pool是从磁盘读取的页面的内存缓存。由于DBMS比OS更了解数据库的实际状况,所以我们想要自己管理内存以及页面。
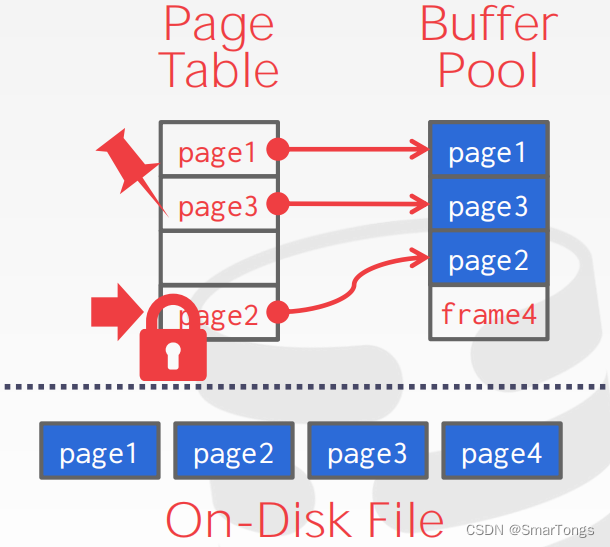
Buffer Pool是一个由固定大小页面数组组织起来的内存区域。数组中的每一项称为frame。当DBMS请求一个页面,一个精确的副本将被放置在其中一个frame中。Buffer Pool维护了以下元数据:
Page Table:内存中的哈希表,用来跟踪当前内存中的页面。它将页面id映射到缓冲区池中的框架位置。(这是一个不需要存储在磁盘上的内存内的数据结构。)
Page Directory的区别:
- 页面目录是页面ID到数据库文件中页面位置的映射,所有的更改都必须记录在磁盘上,以便在重新启动时允许DBMS找到。
Dirty Flag:线程会在它修改一个页面时设置此标志。这向DBMS表明,必须将该页面写回磁盘。
Pin/Reference Counter:这将跟踪当前访问该页面的线程读取数(读取或修改)。线程在访问页面之前必须增加计数器。如果页面的计数大于零,则存储管理器不允许从内存中删除该页面。
分配策略
- 全局策略:DBMS如何为所有活跃的事务进行决策
- 局部策略:将frame分配给指定的事务,不考虑其他并发事务的表现
优化
Multiple Buffer Pools:
DBMS还可以有多个有不同用途的缓冲池。这有助于减少锁存争用并提高局部性
Pre-Fetching:
DBMS还可以根据查询计划通过预抓取页面来进行优化。通常会在按顺序访问页面时完成
Scan Sharing:
查询游标可以附加到其他游标上,并一起扫描页面。DBMS跟踪第二个查询与第一个查询连接的位置,以便在到达数据结构结束时完成扫描。
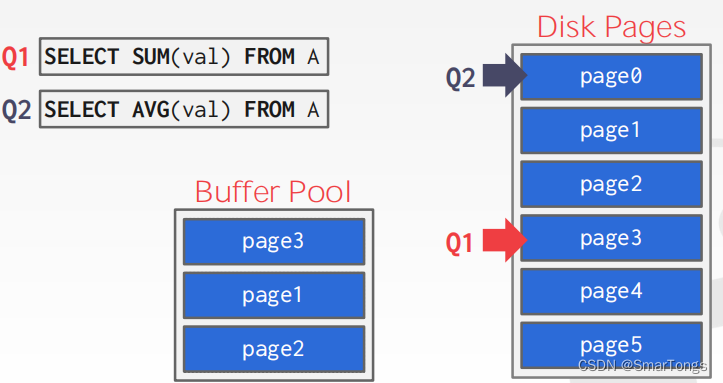
Buffer Pool Bypass:
顺序扫描操作符将不会将获取的页面存储在缓冲池中,正对一些一次性的操作如果全部放入Buffer Pool会不得不替换其他大部分页而导致污染。为避免此种情况为该次查询单独申请一块临时内存,将查询得到的数据放入查询的本地内存而不是Buffer Pool,即用即销,适用于一些数据量不大的join/sort操作
很多磁盘操作都要经过OS API,除非你告知操作系统,否则其会维护自己的文件系统缓存,很多DBMS使用直接I/O(O_DIRECT)来跳过操作系统缓存。因为操作系统缓存会带来冗余副本以及不同的替换策略。
Replacement Policy
替换策略是DBMS实现的一种算法,它可以决定在需要空间时从缓冲区池中删除哪个页面。其实施目标为:
- 要正确: 在某个数据没有被真正使用完前不应被写出或移除
- 求准确: 移除的page尽可能是那些未来不太会用到的page
- 速度快: 在page表中查找时会持有latch
- 体积小: 尽可能小的meta-data
方法
LRU 最近最少用算法
CLOCK 时钟算法
将page围成一个圈, 每个page维护一个访问标志位, 被访问时设置为1, 时针绕圈走动, 时针走过时将标志位为1的重置为0。当需要移除某一页时, 时针最先走到的标志位为0的page可直接移除。这是LRU的一种近似算法, 它每次移除的并是”最”近最少用的page, 而是在”一段时间内”未使用到的page。在某个固定的时间窗内它与LRU是等效的, 在一些简单的点查询时效率很高。
以上方法会导致sequential flooding, 即可能线性扫描大量页导致缓存污染, 解决该问题的算法:
LRU-K
将最近使用过1次的判断标准扩展为最近使用过K次, 只有最近使用过K次才会从历史队列进入缓存队列。核心思想是把时间戳的“绝对”变为”相对“,不是找哪个时间戳“绝对最老”,而是哪个page的“上次访问”和“上上次访问”时间戳间隔最大,它就是最近最不常用的page
localization
本地化。为某些常用的查询创建本地buffer pool,避免污染大的buffer pool
priority hints
当查询执行时,DBMS知道每一页的context,有助于DBMS自主选择替换哪一页。比如当自增索引存在时,数据库在进行多次ID不固定的查询时会选择替换B+树的叶子结点,而不是根节点,因为查询总是从根节点开始。
其中前2种实现难度小,但大公司做的高级数据库往往使用更为复杂也更优秀的其他策略。
dirty page策略选择
- fast: 在需要换入某一页时, 直接找到某一clean的页移除它, 给新页腾位置, 但如果该clean页将来会被用到就将导致效率下降,这只会带来一次IO,即读入需要的页
- slow: 在需要换入某一页时, 写出一个dirty页, 这会直接导致两次磁盘IO,一次是写出dirty页,一次是读入想要的页
成熟的DBMS会有一条线程定时在后台周期性做dirty页写出操作,写出了dirty页之后就可以将其标记为clean
 微信
微信 支付宝
支付宝


