
cmu15-445_IndexConcurrency
索引并发控制
本节讨论让数据结构具备并发安全的特点,尽管本节仅仅是介绍 B+ Tree 上的相关技术。在前两节中讨论的数据结构中,我们都只考虑单线程访问的情况,即只能有一个线程在同时刻访问我们的数据结构。现实中我们是希望多线程在同一时刻访问我们的数据结构。本节课讨论允许多个线程安全地访问我们的数据结构,现在的CPU都是多核,需要考虑到允许多个线程查询和更新。
通常我们会从两个层面上来理解并发控制的正确性:
- 逻辑正确性:(后续讨论)我希望看到的值是我期待看到的值!例如我插入了5这个值,等我插入完后回过头看,5这个值应该存在,而不会是false的。
- 物理正确性:(本节讨论)数据的内部表示是否完好?如何保证线程读取数据时该数据结构的可靠性?
Locks vs Latches
本课程主要研究的是Latches
数据库中特有的 Locks 一般是指行锁、范围锁、表锁这些。用来做事务之间的并发控制。是更为上层的抽象锁。在整个事务期间持有,DBMS需要具有回滚功能。
Latches 就是在多线程编程、操作系统学习中遇到的多线程中接触到的锁,如
mutex、rwlock、semaphore、spinlockde等,来做线程之间的并发控制。是更为底层的锁。在操作期间持有,DBMS不需要有回滚功能。- READ模式:允许多个线程同时读取同一项。另一个任意线程处于读取模式,则当前线程可以获取读取锁存器
- WRITE模式:只允许有一个线程访问该项目。如果另一个线程在任何模式下保持锁存,则线程无法获取写锁存
Latch Implementations
有以下几种方法可以在DBMS中实现Latch。每种方法在工程复杂性和运行时性能方面都有不同的权衡。这些测试和设置步骤是原子地执行的(也就是说,在一个线程检查值之后,但在它更新值之前,没有其他线程可以更新值)。
Blocking OS Mutex 阻塞式操作系统互斥
使用操作系统内置的互斥锁基础设施作为锁存器。futex(快速用户空间互斥锁)由用户空间中的自旋锁和(2)操作系统级互斥锁组成。如果DBMS可以获得用户空间锁存器,则将设置锁存器。它显示为DBMS的一个单一锁存器,即使它包含两个内部锁存器。如果DBMS未能获得用户空间锁存器,那么它就会进入内核,并试图获取一个更昂贵的互斥锁。如果DBMS无法获得这第二个互斥锁,那么线程就会通知操作系统它在锁上被阻止了,然后它就会被取消调度。
操作系统互斥锁在DBMS中通常是一个坏主意,因为它是由操作系统管理的,并且有很大的开销。
Example: std::mutex
Advantages: 在DBMS中不需要额外代码
Disadvantages: 开销大且不易扩展 (about 25 ns per lock/unlock invocation)
Test-and-Set Spin Latch (TAS)
自旋锁存是OS互斥的更有效的替代,因为它是由dbms控制的。自旋锁存器本质上是线程在内存中试图更新的位置(例如,将布尔值设置为true)。线程执行CAS以尝试更新内存位置。如果它不能,那么它旋转在一个时间循环永远试图更新它。Linux的创始人曾经说过:“不要在用用户态使用自旋锁,除非你知道在做什么。”,因为自旋锁在等待的过程中并不知道占用的之前的那个进程什么时候解锁,这有可能会陷入无限等待。
- Example: std::atomic
- Advantages: 上锁/开锁操作效率高(单指令)
- Disadvantages: 不能伸缩且缓存不友好,因为对于多个线程,CAS指令将在不同的线程中执行多次。这些浪费的指令将在高竞争环境中堆积起来;即使线程在做无用功,在OS看来它们也很忙。这将导致缓存一致性问题,因为线程是在其他cpu上轮询缓存线。
- Example: std::atomic
Reader-Writer Latches
互态语言和自旋锁存器并不区分读/写模式(也就是说,它们不支持不同的模式)。我们需要一种允许并发读取的方法,因此如果应用程序有大量读取,它将有更好的性能,因为阅读器可以共享资源而不是等待。读写锁存允许锁存保持在读或写模式。它跟踪有多少线程持有锁存器,并在每个模式下等待获取锁存器。
- Example: This is implemented on top of Spin Latches
- Advantages: 允许并发读取
- Disadvantages: DBMS必须管理读/写队列,以避免出现饥饿状态。由于额外的元数据,比自旋锁存器更大的存储开销
Hash Table Latching
哈希表加锁很方便,因为加锁的方向都是一致的,所有人都是往同一方向走。如果哈希表需要扩容就给全局加一个锁。哈希表加锁按照粒度分为 page latches 和 slot latches 。
Page Latches
首先将哈希表分段的切开,分段加锁,一个线程操作的时候就给这一段加锁,具体这个段你叫作桶、叫做页什么都行,这里我称呼为一段。
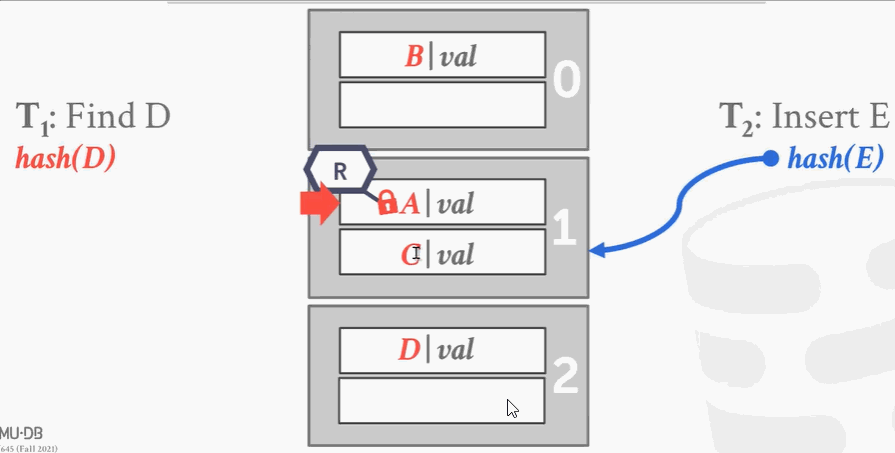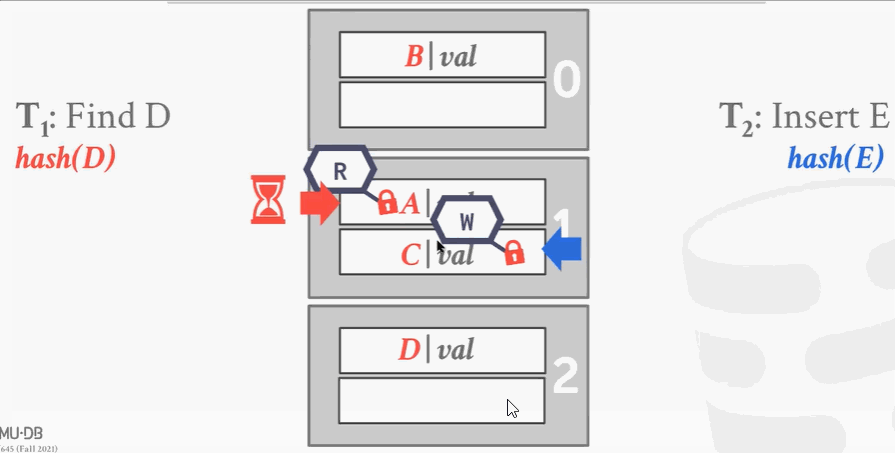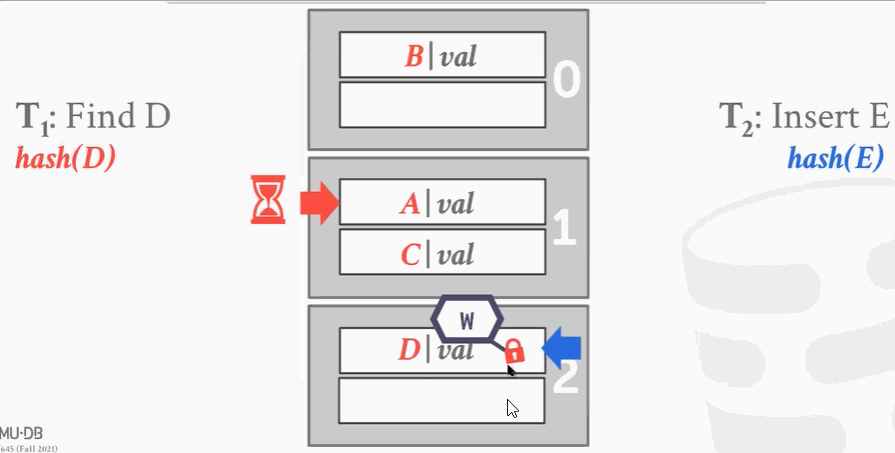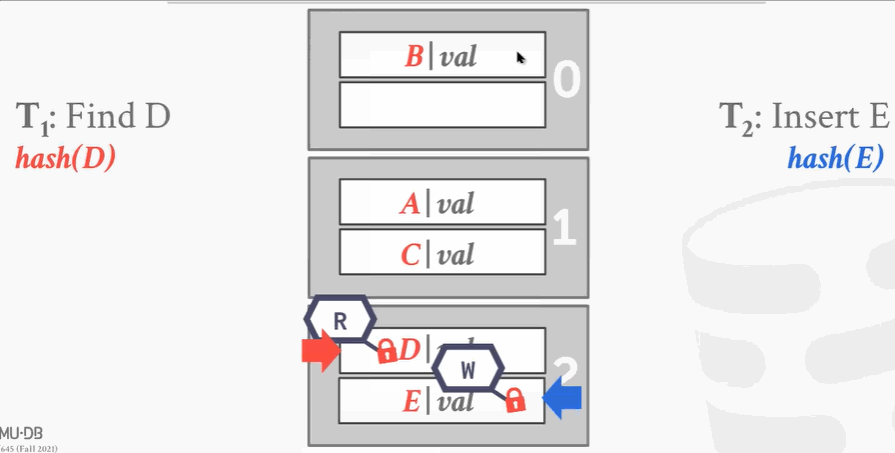
第1个进程想要查找D,经过hash发现D应该在A这个槽里,于是把这个段加读锁。往下遍历的时候,这时候第2个线程来了想插入E,因为锁冲突加不上。第1个线程往下走,解开读锁,给下面的段加上读锁。这时候第2个线程可以进来加写锁。线程1完事了就解锁,线程2把最下面段加写锁,插入数据。
粒度不是很细,维护的锁不是很多。
Slot Latches
按照槽加锁。与之前的一样,只不过粒度更细,更能避免并发冲突,缺点是锁非常多。
Go语言中的map处理方式是存在两个hash表,读写分离,其中一个主的哈希表是只读表,还有一个是写表,然后定期挪数据。好处是读的时候是无锁的。
B+Tree Latching
B+Tree的并发操作与前面的一样,需要允许多线程的读和写。
- 结点内部的数据需要保护。
- 合并分裂的操作也需要保护起来。
B+Tree并发操作存在的问题:
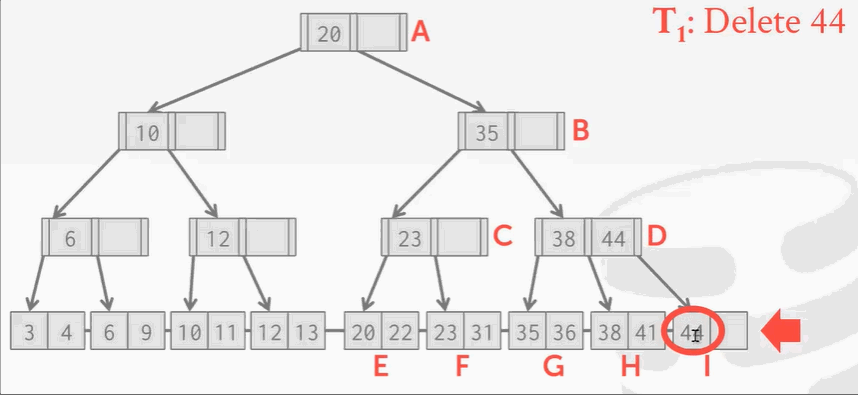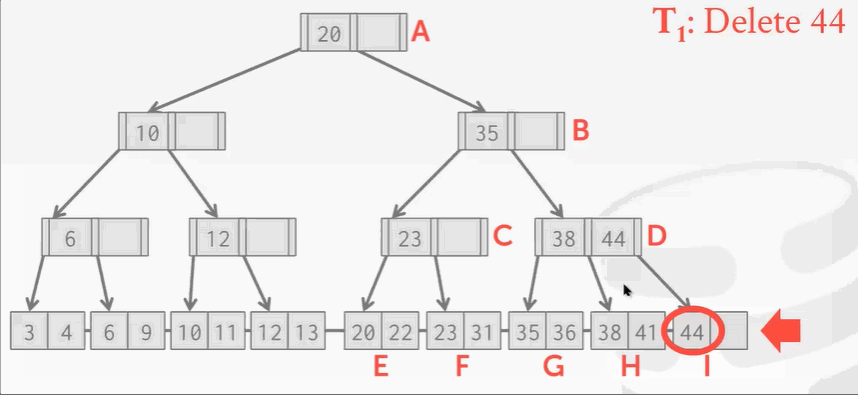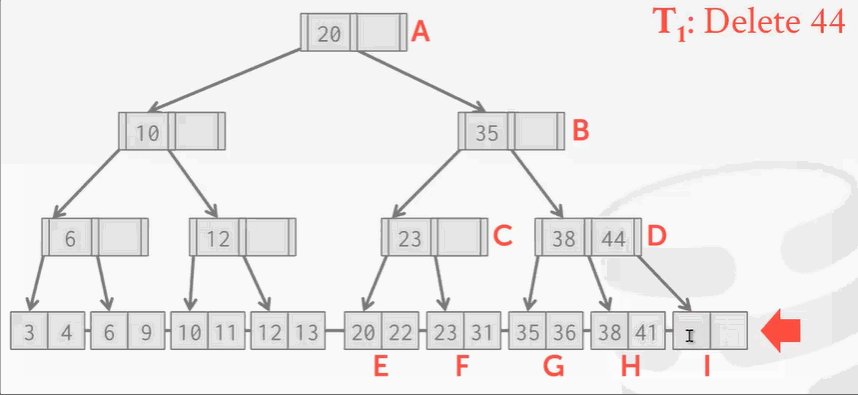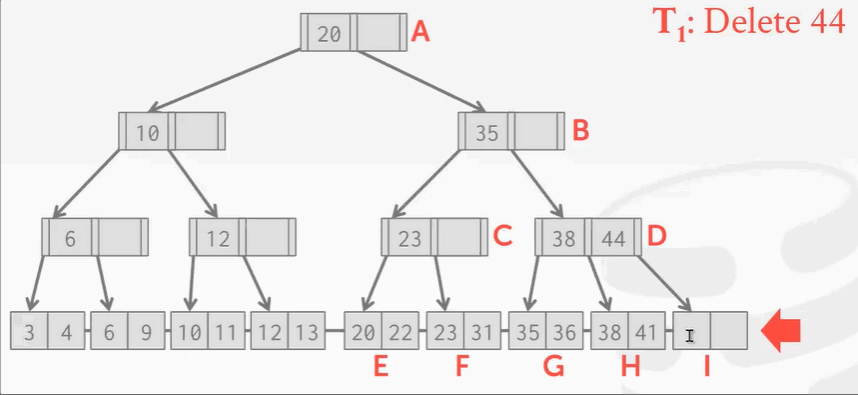
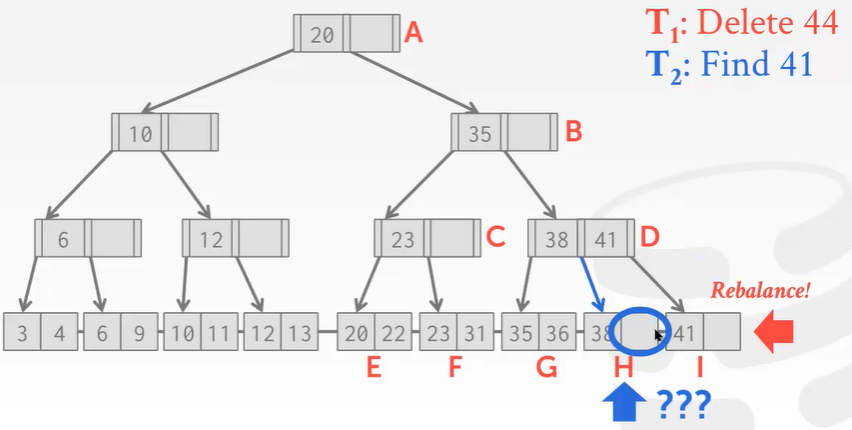
删除操作没什么问题,但是B+Tree在删除结点后需要再平衡。可回顾之前学的树索引删除结点知识。现在I位置的结点被删除掉了,按照B+Tree的规矩,需要将H结点的key 41移动到右边。现在来了另一个线程,刚找到41,准备读的时候发现41并不存在。
Basic Latch Crabbing Protocol:
Search: 从根开始,向下,反复获得子节点上的锁,然后释放父锁。
Insert/Delete: 从根开始,然后向下移动。一旦孩子被锁住了,检查一下它是否安全。如果孩子是安全的,释放它所有祖先的锁。
Improved Lock Crabbing Protocol: 乐观锁
之前我们要锁根节点都是基于我们怕将来要动根节点。但是,我们对数据库的绝大部分操作是动不到根节点的、我们对一个叶子结点的操作是很少引起根节点的变化的。事务在每次删除插入操作的时候都在根节点获得一个排他性的锁限制了并发性。乐观锁即,每个事务都将假定到目标叶节点的路径是安全的,并使用READ锁到达它,并进行验证。如果路径中的任何节点都不安全,则执行之前的算法(即获取写锁存器)。
- Search:和之前一样
- Insert/Delete:在搜索路径上使用READ锁,达到叶节点使用WRITE锁。如果叶子节点不安全,释放所有之前获得的锁,使用之前讨论的锁协议重新执行协议。
Leaf Node Scans
这些协议中的线程以“自上而下”的方式获取锁存器。这意味着线程只能从低于其当前节点的节点获取锁存器。如果所需的锁存器不可用,线程必须等待它可用。有鉴于此,就永远不会有死锁。
叶节点扫描很容易出现死锁,因为现在我们有线程试图同时在两个不同的方向上获取锁(即,从左到左和从右到左)。索引锁存器不支持死锁检测或避免锁定。
因此,我们处理这个问题的唯一方法是通过编码纪律。叶节点兄弟锁存器获取协议必须支持“不等待”模式。也就是说,B+树代码必须处理失败的锁存器获取。这意味着,如果一个线程试图获取一个叶节点上的锁存器,但该锁存器不可用,那么它将立即中止其操作(释放它所持有的任何锁存器),然后重新启动该操作。
 微信
微信 支付宝
支付宝


