
cmu445_Query_Planning_Optimization
背景
SQL 语句让我们能够描述想要获取的数据,而 DBMS 负责来根据用户的需求来制定高效的查询计划。不同的查询计划的效率可能出现多个数量级的差别,如 Join Algorithms 一节中的 Simple Nested Loop Join 与 Hash Join 的时间对比 (1.3 hours vs. 0.45 seconds)。
Query Optimizer 第一次出现在 IBM System R,那时人们认为 DBMS 指定的查询计划永远无法比人类指定的更好。System R 的 optimizer 中的一些理念至今仍在使用。
查询优化技术
Heuristics/Rules
- Rewrite the query to remove stupid/inefficient things
- Does not require a cost model
Cost-based Search
- Use a cost model to evalucate multiple equivalent plans and pick the one with the lowest cost
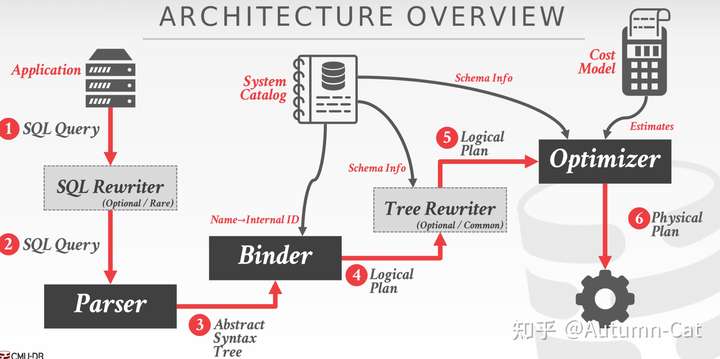
上图为查询执行的整个流程图,这里的 Rewriter 负责 Heuristics/Rules,Optimizer 则负责 Cost-based Search。
Query Rewriting
如果两个关系代数表达式 (Relational Algebra Expressions) 如果能产生相同的 tuple 集合,我们就称二者等价。DBMS 可以通过一些 Heuristics/Rules 来将关系几何表达式转化成成本更低的等价表达式,从而达到查询优化的目的。这些规则通常试用于所有查询,如:
Predicate Pushdown
Predicate 通常有很高的选择性,可以过滤掉许多无用的数据。将 Predicate 推到查询计划的底部,可以在查询开始时就更多地过滤数据,举例如下:


Projections Pushdown
本方案对列存储数据库不适用。在行存储数据库中,越早过滤掉不用的字段越好,因此将 Projections 操作往查询计划底部推也能够缩小中间结果占用的空间大小,举例如下:

Cost-based Search
除了 Predicates 和 Projections 以外,许多操作没有通用的规则,如 Join:Join 操作既符合交换律又符合结合律,等价关系代数表达式数量庞大,这时候就需要一些成本估算技术,将过滤性大的表作为 Outer Table,小的作为 Inner Table,从而达到查询优化的目的。
Cost Estimation:
一个查询需要花费多长时间,取决于许多因素 :
CPU: Small cost; tough to estimate
Disk: #block transfers
Memory: Amount of DRAM used
Network: #messages
但本质上取决于:整个查询过程需要读入和写出多少 tuples。因此 DBMS 需要保存每个 table 的一些统计信息,如 attributes、indexes 等信息,有助于估计查询成本。值得一提的是,不同的 DBMS 的搜集、更新统计信息的策略不同。
Statistics:
通常,DBMS 对任意的 table R,都保存着以下信息:
- : R中的tuples数量;
- : R中A属性的不同取值(distinct values)个数;
- : A属性取值的最大值、最小值;
利用上面两条数据,可以得到 selection cardinality,即 R 中 A 属性下每个值的平均记录个数:。需要注意的是,这种估计假设 R 中所有数据在 A 属性下均匀分布 (data uniformity)。利用以上信息和假设,DBMS 可以估计不同 predicates 的 selectivity:
- ,两个P之间相互独立
Sampling:
现代 DBMSs 也会使用采样技术来降低成本估计本身的成本,面对如下查询,我们可以等间隔从表中对数据采样,当然,为了避免重复采样,DMBS 会保存一份采样表,待 table 的变动较大时,再更新采样表。
1 | SELECT AVG(age) |
 |
 |
|---|---|
Plan Enumeration
当执行完基于规则的重写后,DBMS将针对查询枚举不同的计划,并估计每个计划的开销,DBMS将在穷尽所有可能的查询计划或者超时后选择看到过的最好的计划来执行查询。
对于Single relation:
选择最优的访问方式
Sequential Scan
Binary Search (clustered indexes)
Index Scan
Predicate evaluation ordering
对于Multiple relations:
随着参与链接的表的数量的增加,可能的查询方案数量将指数增长。System R中只考虑left-deep join,但是现代DBMSs并不总是进行这一假设。
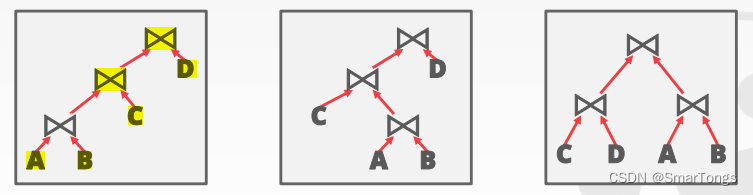
选择left-deep join是因为其允许将中间结果不写入临时文件,实现完全管道流水,但是并不是所有的left-deep join都支持完全管道化操作。
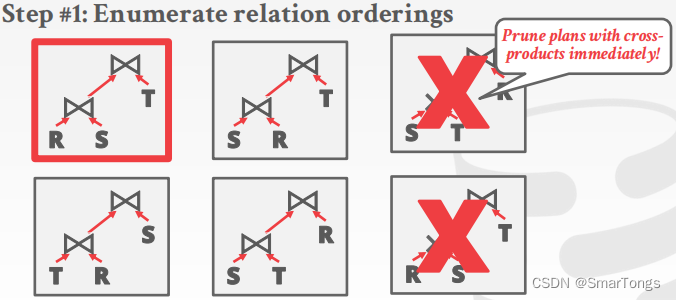
多表查询的一般步骤为:
Enumerate the orderings: Left-deep tree #1, Left-deep tree #2…
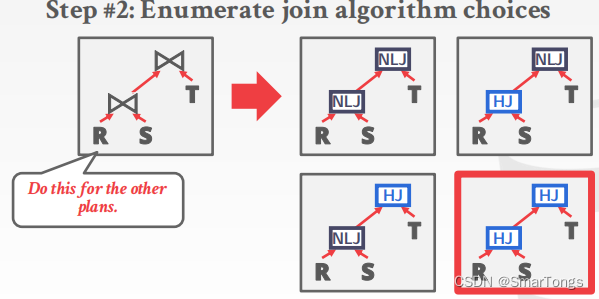
Enumerate the plans for each operator:Hash, Sort-Merge, Nested Loop…
Enumerate the access paths for each table: Index #1, Index #2, Seq Scan…
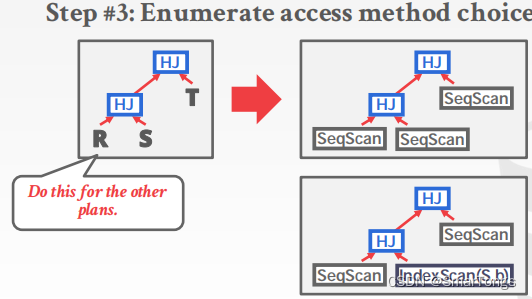
一般使用动态编程来降低开销估计的数量:
|
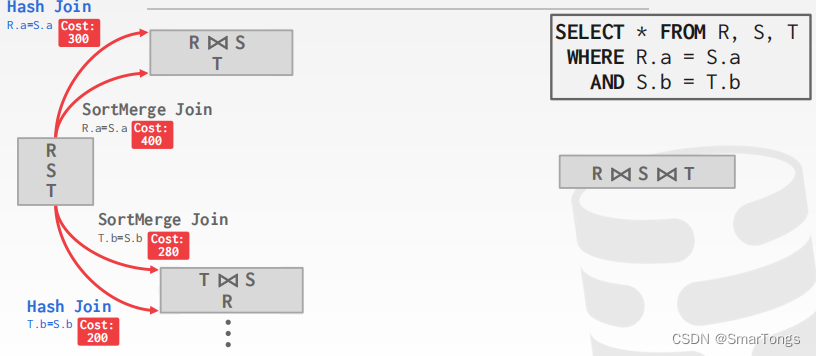 |
|
| :—————————————————————————————: |
|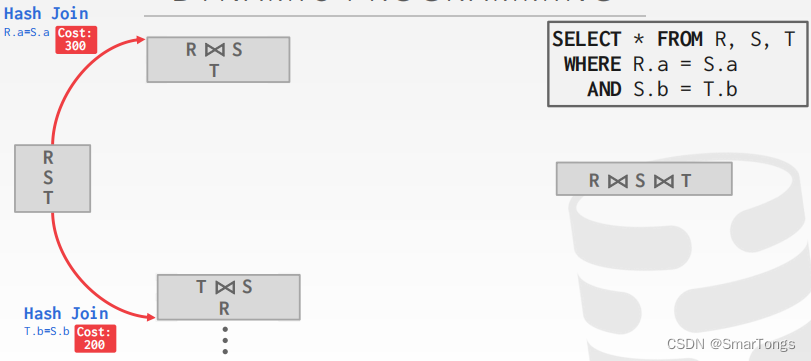 |
|
|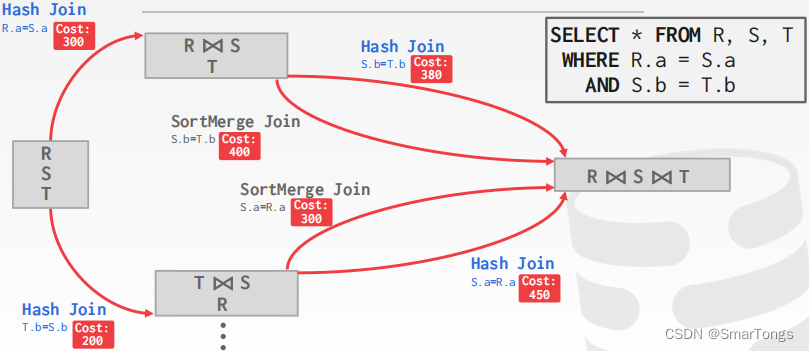 |
|
|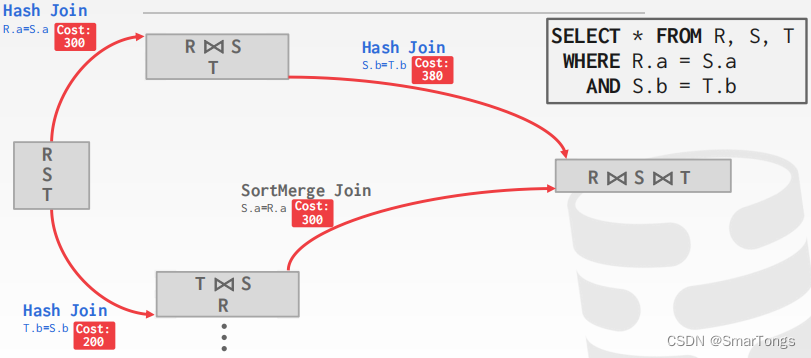 |
|
|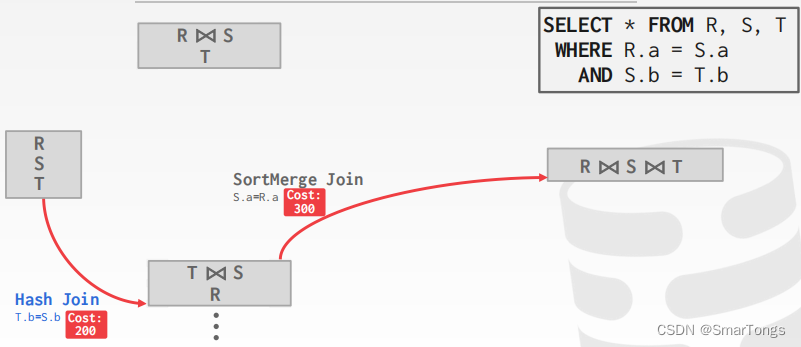 |
|当查询中的表数小于12个时,Postgres使用传统算法,当有12个或更多时切换到GEQO:
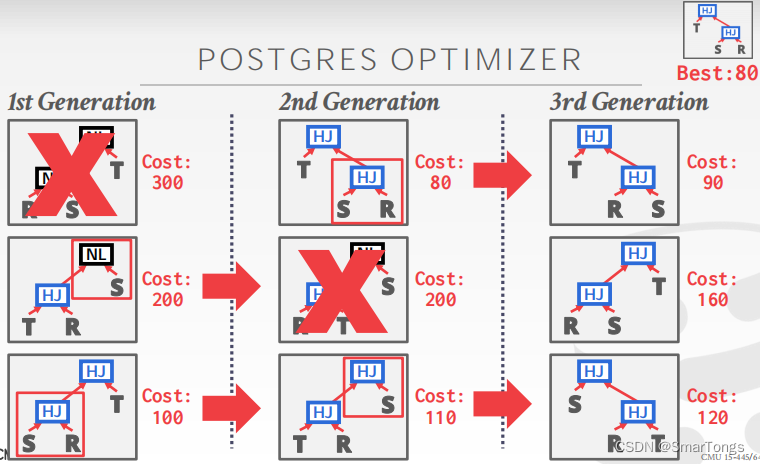
对于Nested sub-queries:
DBMS将where子句中的嵌套子查询视为接受参数并返回单个值或一组值的函数。一般有两种处理方式:
重写以解除关联和/或使它们变平
将嵌套的查询并存储结果分解为临时表

 微信
微信 支付宝
支付宝


