
cmu445_Logging_Schemes
数据库在运行时可能遭遇各种故障,这时可能同时有许多正在运行的事务,如果这些事务执行到一半时故障发生了,就可能导致数据库中的数据出现不一致的现象:

这时就需要故障恢复机制来保证数据库的原子性、一致性、持久性。故障恢复机制包含两部分:
在事务执行过程中采取的行动来确保在出现故障时能够恢复 (本节课)
在故障发生后的恢复机制,确保原子性、一致性和持久性 (下节课)
本节主要内容包括:
Failure Classification
Buffer Pool Policies
Shadow Paging
Write-Ahead Log
Logging Schemes
Checkpoints
Failure Classification
世上并不存在能够容忍任何故障的容错机制,即便做了异地多活,一次小行星撞地球也能将你的系统一举歼灭,因此在讨论故障恢复之前,我们必须先为故障分类,明确需要容忍的故障类型。
一般故障类型可以分为 3 种:
事务故障 (Transaction Failures)
- 逻辑错误 (Logical Errors):由于一些内部约束,如数据一致性约束,导致事务无法正常完成。
- 内部错误 (Internal State Errors):由于数据库内部调度、并发控制,如死锁,导致事务无法正常提交。
系统故障 (System Failures)
- 软件故障 (Software Failure):如 DBMS 本身的实现问题 (NPE, Divide-by-zero)。
- 硬件故障 (Hardware Failure):DBMS 所在的宿主机发生崩溃,如断电。且一般假设非易失性的存储数据在宿主机崩溃后不会丢失。
存储介质故障 (Storage Media Failures)
如果存储介质发生故障,通常这样的故障就是无法修复的,如发生撞击导致磁盘部分或全部受损。所有数据库都无法从这种故障中恢复,这时候数据库只能从归档的备份记录中恢复数据。
Buffer Pool Policies
修改数据时,DBMS 需要先把对应的数据页从持久化存储中读到内存中,然后在内存中根据写请求修改数据,最后将修改后的数据写回到持久化存储。在整个过程中,DBMS 需要保证两点:
- DBMS 告知用户事务已经提交成功前,相应的数据必须已经持久化。
- 如果事务中止,任何数据修改都不应该持久化。
如果真的遇上事务故障或者系统故障,DBMS 有两种基本思路来恢复数据一致性,向用户提供上述两方面保证:
- Undo:将中止或未完成的事务中已经执行的操作回退。
- Redo:将提交的事务执行的操作重做。
DBMS 如何支持 undo/redo 取决于它如何管理 buffer pool。我们可以从两个角度来分析 buffer pool 的管理策略:Steal Policy 和 Force Policy。以下图为例:

如上图所示,有 2 个并发事务 T1 和 T2,T1 要修改 A 数据,T2 要修改 B 数据,A、B 数据都位于同一块数据页上。在 T2 事务提交时,T1 事务尚未结束,这时 T1 已经修改了 A 数据,此时 DBMS 会允许被修改但未提交的 A 数据进入持久化存储吗?在 T2 事务提交时,是否需要将他的数据改动持久化?
Steal Policy: DBMS 是否允许一个未提交事务修改持久化存储中的数据?Steal Policy 有两种可能:允许 (Steal) 和不允许 (No-Steal)。如果选择允许,若 T1 事务回滚,则需要把已经持久化的数据读进来,回滚数据,再存回去;如果选择不允许,即T2在commit的时候需要copy一份A未修改过的数据,若 T1 事务回滚,DBMS 不需要做任何额外的操作。因此这里存在数据恢复时间与 DBMS 处理效率的取舍。
Force Policy: DBMS 是否强制要求一个提交完毕事务的所有数据改动都反映在持久化存储中?Force Policy 有两种可能:强制 (Force) 和非强制 (No-Force)。如果选择强制,每次事务提交都必须将数据落盘,数据一致性可以得到完美保障,但 I/O 效率较低;如果选择非强制,DBMS 则可以延迟批量地将数据落盘,数据一致性可能存在问题,但 I/O 效率较高。
因此我们有 4 种实现组合:
| Steal | No-Steal | |
|---|---|---|
| Force | Steal + Force | No-Steal + Force |
| No-Force | Steal + No-Force | No-Steal + No-Force |
在实践中使用的主要是 No-Steal + Force 和 Steal + No-Force。
Shadow Paging: No-Steal + Force
最容易实现的一种策略组合就是 No-Steal + Force:
- 事务中止后,无需回滚数据,因为该事务修改的数据不会被别的事务捎带落盘;
- 事务提交后,无需重做数据,因为该事务修改的数据必然会被落盘持久化;
当然,这种策略组合无法处理”写入的数据量超过 buffer pool 大小“的情况。
shadow paging 是 No-Steal + Force 策略的典型代表,它会维护两份数据库数据:
- Master:包含所有已经提交事务的数据
- Shadow:在 Master 之上增加未提交事务的数据变动
正在执行的事务都只将修改的数据写到 shadow copy 中,当事务提交时,再原子地把 shadow copy 修改成新的 master。当然,为了提高效率,DBMS 不会复制整个数据库,只需要复制有变动的部分即可,即 copy-on-write。通常,实现 shadow paging 需要将数据页组织成树状结构,如下图所示:

左边是内存中的数据结构,由一个根节点指向对应的 page table,其中 page table 对应着磁盘中的相应的数据页。在写事务执行时,会生成一个 shadow page table,并复制需要修改的数据页,在其上完成相应操作。在提交写事务时,DBMS 将 DB Root 的指针指向 shadow page table,并将对应的数据页全部落盘,如下图所示:

在事务提交前,任何被修改的数据都不会被持久化到数据库;在事务提交后,所有被修改的数据都会被持久化到数据库。在 shadow paging 下回滚、恢复数据都很容易:
Undo/Rollback:删除 shadow pages (table),啥都不用做
Redo:不需要 redo,因为每次写事务都会将数据落盘
shadow paging 很简单,但它的缺陷也很明显:
复制整个 page table 代价较大,尽管可以通过以下措施来降低这种代价:
- 需要使用类似 B+ 树的数据结构来组织 page table
- 无需复制整个树状架构,只需要复制到达有变动的叶子节点的路径即可
事务提交的代价较大:
- 需要将所有发生更新的 data page、page table 以及根节点都落盘
- 容易产生磁盘碎片,使得原先距离近的数据渐行渐远
- 需要做垃圾收集
- 只支持一个写事务或一批写事务一次性持久化
在 2010 年之前,SQLite 采用的就是类似 shadow paging 的策略,当写事务需要修改某页数据时,DBMS 会先将原始数据页保存到一个独立的 journal 文件中,然后再将对应的修改持久化到磁盘中。当 SQLite 重启后,如果发现磁盘中存在 journal 文件,则之间将对应的数据页覆盖到磁盘中即可。
Write-Ahead Log :Steal + No-Force
通过刚才对 shadow paging 的讨论,我们可以发现导致其效率问题的主要原因是:DBMS 在实现 shadow paging 时需要将许多不连续的数据页写到磁盘中,随机写对磁盘来说并不友好,如果能将这种随机写入转化为顺序写入,那么效率自然能够提升。于是 WAL 来了。
WAL 指的是 DBMS 除了维持正常的数据文件外,额外地维护一个日志文件,上面记录着所有事务对 DBMS 数据的完整修改记录,这些记录能够帮助数据库在恢复数据时执行 undo/redo。
使用 WAL 时,DBMS 必须先将操作日志持久化到独立的日志文件中,然后才修改其真正的数据页。通常实现 WAL 采用的 buffer pool policy 为 Steal + No-Force,下面我们将详细地介绍 WAL Protocol。
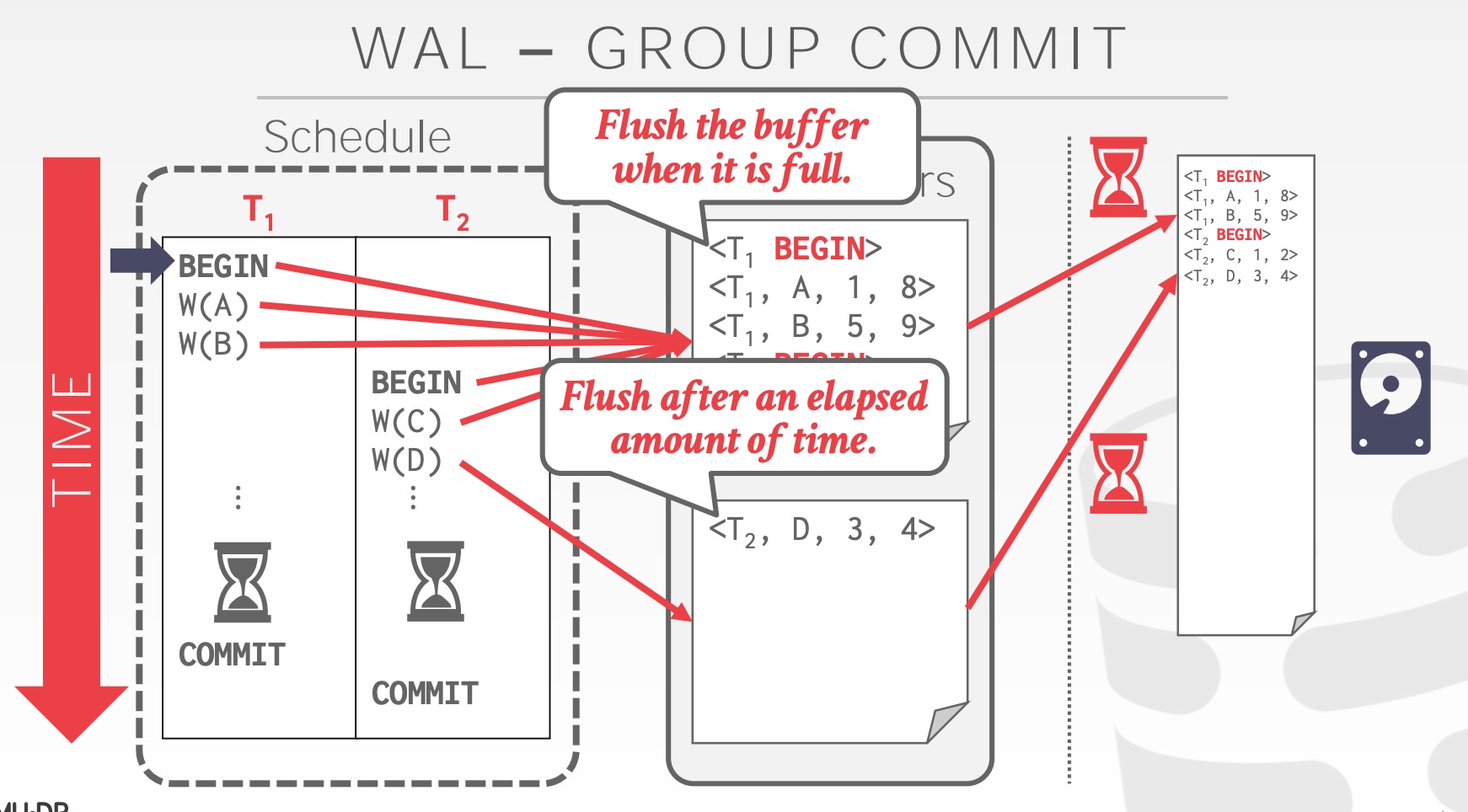
***WAL Protocol:***- DBMS 先将事务的操作记录放在内存中 (backed by buffer pool)
- 在将 data page 落盘前,所有的日志记录必须先落盘
- 在操作日志落盘后,事务就被认为已经提交成功
事务开始时,需要写入一条 <BEGIN> 记录到日志中;事务结束时,需要写入一条 <COMMIT> 记录到日志中;在事务执行过程中,每条日志记录着数据修改的完整信息,如:
Transaction Id (事务 id)
Object Id (数据记录 id)
Before Value (修改前的值),用于 undo 操作
After Value (修改后的值),用于 redo 操作
每次事务提交时,DBMS 都必须将日志记录落盘,由于落盘的操纵对于内存操作来说用时较长,因此可以利用 group commit 来批量刷盘从而均摊落盘成本。
通过以上的分析,我们可以发现,不同的 buffer pool policies 之间存在着运行时效率与数据恢复效率间的权衡:

运行时效率:No-Steal + Force < Steal + No-Force(WAL)
数据恢复效率:No-Steal + Force > Steal + No-Force(WAL)
大部分数据库更看重运行时效率,因此几乎所有 DBMS 使用 No-Force + Steal 的 buffer pool policy。
Logging Schemes
在记录操作信息时,通常有两种方案:physical logging 和 logical logging。前者指的是记录物理数据的变化,类似 git diff 做的事情;后者指的是记录逻辑操作内容,如 UPDATE、DELETE 和 INSERT 语句等等。
logical logging 的特点总结如下:
相比 physical logging,记录的内容精简
恢复时很难确定故障时正在执行的语句已经修改了哪部分数据
恢复时需要回放所有事务,这个过程可能很漫长
- 当有并发事务时,逻辑日志难以进行故障恢复
还有一种混合策略,称为 physiological logging,这种方案不会像 physical logging 一样记录 xx page xx 偏移量上的数据发生 xx 改动,而是记录 xx page 上的 id 为 xx 的数据发生 xx 改动,前者需要关心 data page 在磁盘上的布局,后者则无需关心,举例如下:
- 基于slot记录tuple
- 允许DBMS在写入一个长记录之后重新整理pages

physiological logging 也是当下最流行的方案,混合记录。
Checkpoints
如果我们放任 WAL 增长,它可以随着新的操作执行而无限增长。如此这般,在故障恢复时,DBMS 需要读取更多的日志,执行更多的恢复和回滚操作。
为了避免这种情况出现,DBMS 需要周期性地记录 checkpoint,即将所有日志记录和数据页都持久化到存储设备中,然后在日志中写入一条 <CHECKPOINT> 记录,举例如下:

当 DBMS 发生崩溃时,所有在最新的 checkpoint 之前提交的事务可以直接忽略,如 T1。T2 和 T3 在 checkpoint 前尚未 commit。其中,T2 需要 redo,因为它在 checkpoint 之后,crash 之前提交了,即已经告诉用户事务提交成功;T3 需要 undo,因为它在 crash 之前尚未 commit,即尚未告诉用户事务提交成功。
实现 checkpoints 有需要要考虑的问题:
在于要保证 checkpoint 的正确性,我们需要暂停所有事务
故障恢复时,扫描数据找到未提交的事务可能需要较长的时间
如何决定 DBMS 执行 checkpoint 的周期,太频繁将导致运行时性能下降;等太久将使得 checkpoint 的内容更多,更耗时,同时数据恢复也要消耗更长的时间
Conclusion
WAL 几乎永远是最佳选择。
转载:https://zhenghe.gitbook.io/open-courses/cmu-15-445-645-database-systems/logging-schemes
 微信
微信 支付宝
支付宝


