
Active Storage For Large-Scale Data Mining and Multimedia
这篇发表在VLDB上的文章较早地提出利用DISK上计算资源实现数据预处理达到计算加速;
Abstract
处理器、存储器性能的提升以及成本的下降使得系统智能从CPU向外围设备迁移。存储系统的设计者们正在利用这些额外的计算资源在存储设备内部实现更加复杂的处理和优化。文章提出了Active Disks系统,该系统可以利用单个磁盘上的处理能力来运行应用层级的代码。将应用程序的处理需求部分迁移到磁盘驱动器上执行可以极大减少数据搬运,同时可以利用大多数系统中存储系统的并行性。
文中随后探讨了数据库、数据挖掘、多媒体领域可以受益于该系统的一些应用。提出一个分析模型用来分析基于该系统的扫描密集型应用可能的性能提升。在数据量足够大的前提下,该模型在数百个磁盘组成的阵列中可以实现线性加速。
Introduction
本文评估了利用嵌入式单存储设备处理器运行在数据挖掘、多媒体数据库领域比较常见的数据密集型应用的性能优势。应用程序的发展呈现出生成大量复杂数据集,且通常通过扫描操作处理。很快众多商用存储设备将具备处理并行计算以及高选择性过滤(high-selectivity)的能力,从而减少许多应用程序的执行时间。
主要利用四种应用在host端和disk端进行比较:高维数据库中的最近邻搜索、规则挖掘中的频繁数集计数、图像中的边监测、医疗数据库中的图像注册。所有的这些应用中的处理都是扫描密集型的,这是因为数据或应用本身的特性或者高维数据查询不能很好的被传统索引技术加速。
Active Disks主要从两方面优化I/O受限的扫描操作:1)并行性,数据被划分在众多磁盘上;2)带宽降低,高选择性的过滤操作或者只计算汇总统计信息的扫描操作将从磁盘转移很少一部分数据到主机端。
Background
相对于原始磁盘的带宽限制,现代系统存在有限的外围互连带宽的限制,如表中的系统总线列所示。我们看到,可以读入大量磁盘控制器的内存的MB/s比传递到主机处理器的MB/s要多。在这种情况下,主机的功率与大型扫描的总体带宽限制无关。
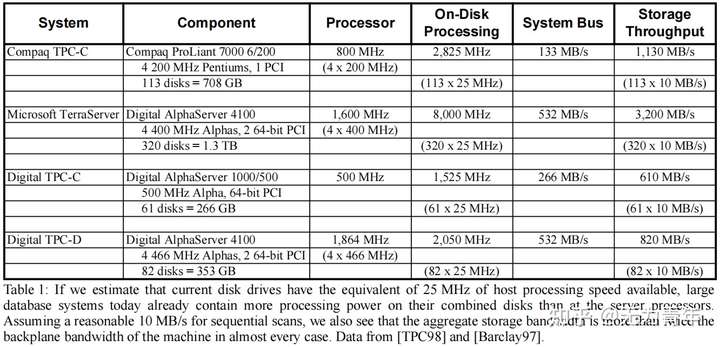
如果我们接下来考虑对数据库机器中特殊用途硬件的成本和复杂性的反对意见,技术趋势再次改变了权衡。如今,在廉价的CMOS微芯片中,晶体管数量的增加可能会增加,这正在推动微处理器在日益简单和廉价的设备中的使用。网络接口、外围适配器、数码相机、图形适配器、阵列控制器和磁盘驱动器都有微控制器,其处理能力超过了15年前的主机处理器。
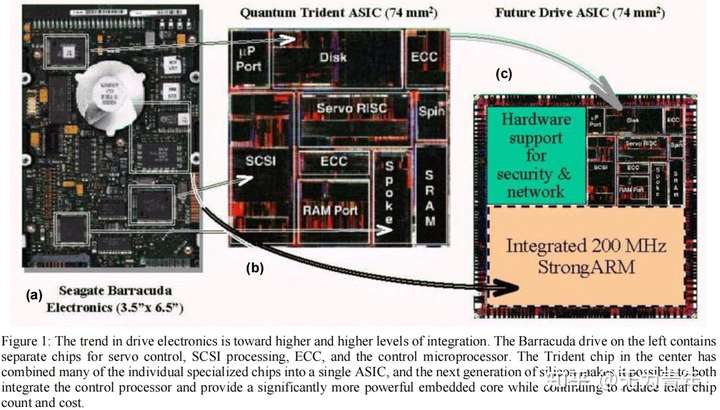
在图1中,我们展示了增加晶体管计数对磁盘电子硬件的影响。图1a提醒我们,除了驱动器控制的专门硬件,磁盘驱动器的电子设备还包括一个简单计算机的所有组件:一个微控制器,一些RAM,和一个通信子系统(SCSI)。图1b显示,这种特殊的控制硬件已经在很大程度上集成到当前一代磁盘中的单个芯片中。驱动器和存储子系统内部的处理能力已经成功地用于优化诸如SCSI等标准化接口背后的功能。使用Active Disks,除了支持这些现有的存储特定的优化外,存储设备中的多余计算能力还可以直接用于特定于应用程序的功能。Active Disks并没有像15年前设想的那样将数据库功能蚀刻到硅上,而是用软件进行编程,并使用通用的微处理器。对数据库机器的第三个反对意见是,全扫描操作的效用有限。然而,各种新兴的应用程序都需要对大量数据进行连续扫描。
在多媒体领域中用户时常需要按内容搜索,用户提供了一个理想的图像,并请求一组相似的图像。这种搜索的一般方法是从每幅图像中提取特征向量,然后搜索这些特征向量的最近邻。众所周知,但直到最近在数据库文献中强调对于高维数据,序列扫描与索引方法同样具有有竞争力。传统的数据库的经验是,索引总是比扫描更加提高性能。这对于低维,或者仅对少数属性的查询有效。然而,在高维数据和最近邻查询中,地址空间中有很多的“空间”,数据点之间距离很远。无论如何,最近的邻居查询都必须访问数据库的很大一部分,从而有效地将问题减少为顺序扫描。
在数据挖掘领域,关联发现和分类等算法也需要对数据进行重复扫描。除了支持复杂的、基于扫描的查询外,趋势是走向越来越大的数据库规模。医学图像数据库也施加了类似的重数据要求。大型数据库意味着许多磁盘,因此也意味着高度并行的活动磁盘系统。
Basic Approach
对于Active Disks来说,较好适用的远程函数具有以下基础特征:1)可以利用大量磁盘组成系统中的并行性;2)使用少量的状态进行操作,处理从磁盘“流过”的数据;3)每个字节执行的指令数量相对较少。本部分主要是为此类应用的性能提出一个分析模型,该模型旨在对Active Disks相对于传统服务器的性能有一个直观的感受。同时基于上述三个特征假设:磁盘传输、磁盘计算、互连传输和主机计算可以通过流水线化和重叠,启动和后处理成本可以忽略不计,而且互连传输速率总是超过单个磁盘速率。涉及的数学表达符号如下:

首先考虑传统的服务器,整体运行时间取管道中的最大值:磁盘读取时间、磁盘互连传输时间、服务器处理时间。即:
对于Active Disks系统来说,相对的磁盘读取、互连传输(处理结果通过互联传输)和磁盘上处理时间包含在以下公式中:
吞吐量至少有三个限制因素:聚合磁盘带宽、存储互连带宽和聚合计算带宽。
将相对参数带入到表达式中得到:
该公式描述了Active Disks系统的基础优势。具有高选择性(large $\alpha_N$)的应用相对受互联带宽制约少一点,布局很多磁盘($d\cdot\alpha_s$>1)的系统将实现较为高效的并发处理。
Estimating System Ratios
文章讨论的应用操作的selectivity大概在$100 - 10^8$之间,其提供的吞吐可能在传统系统中需要具有无线互联带宽才能达到。实际上,这使得提出的系统可以适用更低的互联带宽从而降低成本。此外Active Disks的处理能力要比传统服务器的CPUs弱,在文章的实验中第一代Active Disks CPUs无法以磁盘的速率进行数据扫描。
最后也是最重要的系统参数是Active Disks相对于服务器处理速度的比率,磁盘驱动器中大约是100-200 MHz的微处理器,单个服务器CPU为500-1000 MHz。也就是说$\alpha_s=\frac{1}{5}$。在此种情况下,当有超过5个disks并行工作时Active Disks的处理能力就会超过服务器。
Implications of the Model
下图说明了对于Active Disks系统而言基本的trade-offs。

虚线A代表两个系统中理论上的磁盘限制。我们考虑到Active Disks并不能和许多应用的磁盘数据迁移速度保持一致,即$s_{cpu}^,<w\cdot r_d^, (1)$,因此Active Disks的聚合吞吐实际上要低于虚线A,如虚线B所示。
Active Disks在虚线C上侧吞吐量达到饱和,此时$throughput_{active}= r_n^,\cdot\alpha_N \leq min(d\cdot \frac{s_{cpu}^,}{w},d\cdot r_d^, )$。传统服务器系统可能既存在带宽瓶颈也存在服务器CPU瓶颈。如虚线D所示,在Y点左侧传统系统是磁盘受限的。在X点左侧Active Disks系统因为相对较低的CPU资源而低于传统服务器系统。在Z点右侧Active Disks系统也存在带宽瓶颈。特别的在X点之后Active Disks的吞吐超过了传统系统,结合(1)式我们有$X\cdot s_{cpu}^,/w \leq s_{cpu}/w$,即得到:
如果我们将性能加速定义为Active Disks相对于传统服务器的吞吐之比,那么当$d<1/\alpha_s$时,传统服务器更快,当$1/\alpha_s<d<\alpha_N$时,speedup为:
当$d>\alpha_N$时,speedup为:
我们不考虑X点左侧的speedup因为此种情况独立于应用参数,因此可以利用查询优化器来决定何时将scan通过传统方式执行,何时将scan通过drives执行。
随着处理器和磁盘带宽的不断增长(the ratio of processing power to disk bandwidth in both systems to increase by 15% per year),A和B的差距将逐渐变小。
Applications
Database - Nearest Neighbor Search
我们的第一个应用程序是标准数据库搜索上的一个变体,它确定了数据库中最接近特定输入项的k个属性项。我们使用来自IBM Almaden的合成数据,其中包含申请贷款的个人记录,并包括9个独立属性的信息:
age, education, salary,commission, zip code, make of car, cost of house, loan amount, years owned
在对大量属性进行这样的搜索中,已经证明了对整个数据库的扫描与构建广泛的索引一样有效。基本应用程序使用目标记录作为输入,并处理来自数据库中的记录,始终保持迄今为止最接近的k个匹配项的列表,如果当前记录比列表中已经有的任何记录更接近,则将其添加到列表中。距离,为了比较的目的是每个属性范围内的简单笛卡尔距离的和。对于分类属性,我们使用汉明距离,如果值完全匹配,则分配的距离为0.0,否则分配距离为1.0。
在Active Disks系统中,为每个磁盘分配了整数个记录,并直接在驱动器上进行比较操作。中央服务器将目标记录发送到每个磁盘,这些磁盘确定了数据库中最接近的10条记录。这些列表被返回到服务器,服务器将它们组合以确定最近的10条记录。因为该应用程序将任意大小的数据库中的记录减少为一个包含10条记录的恒定大小的列表,选择性是任意大。最后,磁盘所需的状态只是k个最近记录列表的存储。
Data Mining - Frequent Sets
第二个应用程序是用来发现销售交易中的关联规则的先验算法(Apriori)的实现。下边是Apriori算法的伪代码,$\varepsilon$是支持度阈值,T是交易数据库(是一个multi-set,允许元素重复)。$C_k$是阶段$k$的候选集。算法的每一步都从前一级的大项目集中生成候选集。$count[c]$访问代表候选集$c$的数据结构的字段,初始化为0。最重要的部分是用于存储候选集以及计算频率的数据结构。
1 | Apriori(T, ε) |
我们使用使用来自Quest组的工具生成的合成数据来创建包含来自假设的销售点信息的交易的数据库。每条记录都包含一个
对于Active Disks,每个阶段的计数部分直接在驱动器上执行。中央服务器生成候选k项集的列表,并将此列表提供给每个磁盘。每个磁盘在本地计数其事务的部分,并将这些计数返回给服务器。然后,服务器组合这些计数,并生成一个候选(k+1)项集列表,并将其发送回磁盘。该应用程序将数据库中任意大量的事务减少为一个单一的、不同大小的汇总统计数据集——项集计数——可用于确定数据库中的关系。磁盘所需的状态是候选k项集及其在每个状态的计数。
Multimedia - Edge Detection
对于图像处理,我们研究了一个可以检测一组灰度图像中的边和角的应用程序。我们使用了来自阿尔马登城堡的真实图像,并试图在圣何塞上方的景观中检测到奶牛。该应用程序处理一组256 KB的图像,并使用一个固定的37个像素的掩码,只返回在数据中找到的边缘。其目的是对一类图像处理应用程序进行建模,其中一个图像中只有一组特定的特征(例如,边缘)是重要的,而不是整个图像。这包括跟踪,特征提取,以及定位,这些程序只处理原始图像数据的一个小子集。这个应用程序比前两个应用程序的比较和计算要密集得多。

使用活动磁盘系统,对每个映像的边缘检测直接在驱动器上执行,只有边缘被返回到中央服务器。图3中对原始图像的请求只返回右边的数据,这可以更紧凑地表示。该应用程序将传输到服务器的数据量减少了很大一部分(从此特定图像的256 KB减少到9KB)。磁盘上需要的状态是作为一个整体进行缓冲和处理的单个映像的存储。
Multimedia - Image Registration
我们的第二个图像处理应用程序执行MRI脑扫描分析处理的图像配准部分。图像配准确定了相对于参考图像进行配准(旋转和平移)图像所需的参数集,以补偿扫描期间主体的运动。该应用程序处理一组384 KB的图像,并为每个图像返回一组配准参数。这种应用是研究中计算最密集的。该算法执行快速傅里叶变换(FFT),确定傅里叶空间中的参数,并对得到的参数计算一个逆FFT。除此之外,该算法可能需要一个可变的计算量,因为它是解决一个优化问题使用一个可变数量的迭代收敛到正确的参数。与其他应用程序不同,该算法的每字节成本随着正在处理的数据而显著不同。本一节中讨论的每种算法的平均计算成本如下一节中的表2所示。
对于活动磁盘系统,此应用程序的操作方式类似于边缘检测。参考图像提供给所有驱动器,每个处理图像的配准计算直接在驱动器上执行,只有最终参数(每个图像1.5KB)返回给中央服务器。该应用程序减少了大量固定比例的传输到服务器的数据量。磁盘上需要的状态是参考映像和当前映像的存储器。
Prototype / Experiments
我们的实验测试台包含10个活动磁盘原型,每一个都是一个6年的DECAlpha3000/400(133MHz,64MB,Digital UNIX 3.2g)和两个2.0 GB希捷ST52160 Medalist磁盘。对于服务器情况,我们使用一个DEC AlphaStation S500/500(500MHz,256MB,数字UNIX 3.2g)和4个4.5 GB希捷ST34501W猎豹磁盘在两条超宽SCSI总线(带宽超过服务器可以使用的带宽)。所有这些机器都通过一个以太网交换机和一个155 Mb/s的OC-3 ATM交换机连接。
我们的实验比较了具有直接连接SCSI磁盘的单个服务器机器与具有网络连接活动磁盘的同一台机器的性能,在我们的原型中,每个活动磁盘都是带有两个直接连接SCSI磁盘的工作站。在活动磁盘实验中,当我们增加磁盘的数量时,我们就增加了处理的总数据量,所以我们报告的结果是两个系统的吞吐量(MB/s)。这些结果都显示了活动磁盘的显著改进,并巩固了第3节的模型提供的直觉。
Database - Nearest Neighbor Search

图4比较了单个服务器系统与当磁盘数量从1个增加到10个时具有活动磁盘的系统的性能。正如我们的模型所预测的,我们看到对于少量磁盘,单个服务器系统的性能更好。服务器处理器的功能是单个活动磁盘处理器的四倍,可以以全磁盘速率执行计算。我们看到服务器系统的CPU饱和在25.7 MB/s,性能没有改善增加两个磁盘,而活动磁盘系统继续线性扩展到58 MB/s与10个磁盘。
Data Mining - Frequent Sets

在图5中,我们展示了频繁集应用程序(1项集和2项集)的前两次传递的结果。我们再次看到了四个驱动器的交叉点,服务器系统瓶颈在8.4 MB/s,性能不再改善,而活动磁盘系统继续线性扩展到18.9 MB/s。图5b说明了频繁集应用程序的一个重要属性,该属性会影响特定的分析是否适合在活动磁盘上运行。该图表显示了两个不同数据库上的一系列输入支持值之间的内存需求。支持值越低,在连续的阶段中生成的项目集就越多,而必须保持在磁盘上的状态数据就越大。我们预计支持度将倾向于更高的值,因为很难处理大量的规则,而且支持度越低,生成的规则的吸引力就越小。但是,对于非常低的支持值,活动磁盘上有限的内存可能会成为一个问题。现在的现代磁盘驱动器包含1 MB到4 MB的缓存内存,所以我们可能期望在活动磁盘可用的时间框架内使用4-16 MB。这意味着在设计算法和选择何时利用磁盘上的执行时必须小心。(不仅是时间上的考量,还有计算资源上的考量)。
Multimedia

图6显示了图像处理应用程序的结果。正如我们在表2中所看到的,图像处理应用程序比搜索和频繁项集需要更多的CPU时间,导致这两个系统的吞吐量都大大降低。边缘检测瓶颈会使服务器CPU达到1.4 MB/s,而活动磁盘系统可扩展到3.2 MB/s。图像配准是我们考虑过的cpu最密集的应用程序。它在服务器系统上只能实现225 KB/s,并通过10个活动磁盘扩展到650 KB/s。
Model Validation
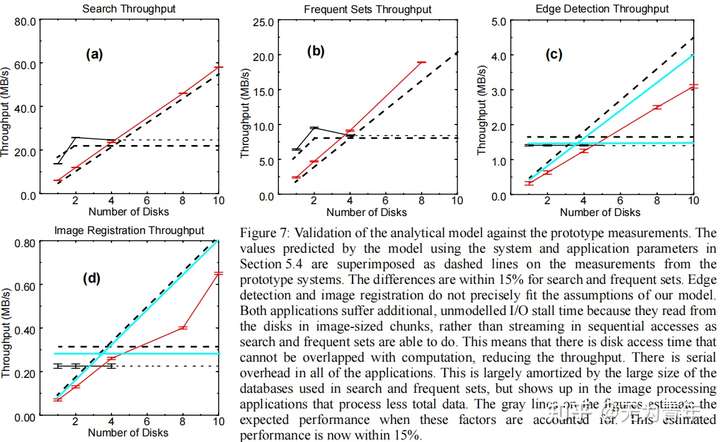
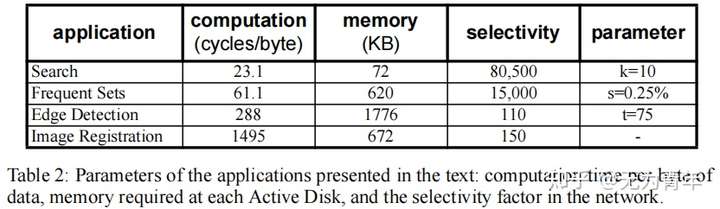
图4、图5和图6的图表证实了第3节中模型的形状。为了确认这些值,我们需要这个测试样例的具体参数。$\alpha_s=133/500=1/3.8$(直接从时钟速率估计,因为处理器使用相同的基本芯片,并且在两种情况下的代码是相同的)。理想条件下$\alpha_d=\alpha_n=1$,但是在测试样例中实际上$r_d=14MB/s, r_d^,=7.5MB/s, r_n=60MB/s$以及$ r_n^,=10MB/s$。估计应用程序的选择性是一个简单的计算字节操作,如表2所示。
估计每个字节的循环数并不是那么简单。我们首先仪器安装每个应用程序的服务器实现,以确定当所有代码和数据都在本地缓存时,整个计算所花费的总周期数,并将其除以处理的字节总数。这忽略了形成、发行和完成物理SCSI磁盘操作的成本,在之前的研究中,以150 MHz Alpha测量为0.58微秒或每字节10.6个周期。我们将其添加到我们的“热缓存”数字中,并报告表2中每个应用程序所需的每个字节周期的结果估计值。
图7结合了所有四个应用程序的结果,并叠加了基于这些系统和应用程序参数的模型的预测。搜索和频繁集的应用显示出模型和测量值之间有很强的一致性。搜索和频繁集的应用显示出模型和测量值之间有很强的一致性。然而,其他两个应用程序与模型预测有显著不同。这些应用程序的问题是,它们还没有将所有的磁盘访问与计算重叠。例如,边缘检测应用程序作为单个请求读取256 KB图像,并且由于操作系统预读取不够深,因此在获取每个图像时导致额外的失速时间。在应用程序中使用异步请求或更激进的预取应该可以纠正这种低效率。造成这个错误的另一个因素是应用程序的串行部分,它对图像处理应用程序的影响更严重,因为它们处理的总数据比其他两个要少。
为了估计重叠得到改进后这些应用程序的性能,我们估计了每个应用程序所经历的总失速时间,并从应用程序运行时间中减去它。我们将这些“改进的”原型估计数作为图7c和d中的额外行来报告。通过此修改,我们的模型预测所有应用程序的性能在15%以内。鉴于我们的目标是使用该模型来发展对活动磁盘应用程序的性能的直觉,这些都是强有力的结果。
Discussion
使用活动磁盘的最大单一好处,以及我们实验中的主要效果,是在大型存储系统中可用的并行性。尽管磁盘驱动器上的处理能力总是低于顶级服务器上的CPU,但磁盘上的聚合CPU能力往往比服务器上的更多。可以利用这种并行性进行分割,并且可以在服务器和驱动器cpu之间“分割”的应用程序,比仅在服务器上运行的应用程序具有更高的总计算能力。
活动磁盘的另一个大好处是能够通过对磁盘进行过滤来显著减少互连带宽。在今天使用的许多系统中,互连带宽比计算能力更高,而且经常是一个重大的瓶颈。如果应用程序正在扫描大型对象以只选择特定的记录或字段或收集汇总统计信息,否则跨互连移动的大量数据将被丢弃,这大大减少了瓶颈。
这两个优点是本文的重点,因为它们承诺了一个数量级的潜在改进。然而,在存储系统研究中,最常见的特定于应用程序的优化是磁盘操作的调度、批处理和预取。活动磁盘也可以期望执行这些类型的远程功能。特别是,我们可能期望活动磁盘作为磁盘定向的I/O模型的一部分参与,该模型使用磁盘上的本地信息进行优化。或者在预取系统中,磁盘提供关于未来访问的提示。(不仅可以用来加速计算,也可以用来加速访存)。
这些常见优化的一个很有希望的变体是互连传输调度。虽然网络调度本身不能像我们在本文中看到的那样产生好处,但它可以成为复杂操作的活动磁盘计算中不可分割的一部分,如散列连接或排序变体。关键的观察是,如果数据将通过网络移动从磁盘读取后,可以发送到“正确”在活动磁盘控制下,减少网络流量通过调度在磁盘,而不是发送到“错误”的地方,然后处理节点之间的通信。
考虑一个跨工作站网络运行的并行示例排序算法,它类似于NowSort的设置。该算法由采样阶段和排序阶段组成。在样本阶段,读取总数据的一个子集,并创建一个直方图,允许将密钥空间划分为n个大致相等大小的桶。在这种类型的并行服务器(集群)版本中,整个数据集然后是1)从节点的本地磁盘中读入节点;2)根据密钥空间分布进行跨网络交换;3)在每个节点上进行本地排序;4)在每个节点上进行本地排序。
在活动磁盘系统中使用网络调度,我们可以通过让驱动器同时执行读取和分发操作来消除步骤2的需要。驱动器不是将所有数据发送到特定节点,而是获得在样本阶段确定的键范围,并响应来自客户端n的请求,只将“属于”客户端n的数据作为键空间的一部分。这意味着针对特定节点的数据将尽快到达该节点,并且永远不需要在节点之间进行交换。这将整个网络中所有数据的传输次数从三次减少到两次。在网络是瓶颈资源的系统中,这将使算法的整体性能提高多达三分之一。
Related Work
在直接连接到单个磁盘的处理元素中执行了广泛的函数的基本思想,例如:CASSM [Su75]、RAP[Ozkarahan75]。由于当时磁盘的性能有限以及构建和编程只能处理有限功能的专用硬件的复杂性,这些机器因此不受欢迎。相反,数据库研究开发了带有商品处理元素的大规模、无共享的数据库服务器。最近有人提出,逻辑扩展是在可编程的“智能”系统外设内执行所有的数据库处理[Gray97]。相反,数据库研究开发了带有商品处理元素的大规模、无共享的数据库服务器。最近有人提出,逻辑扩展是在可编程的“智能”系统外设内执行所有的数据库处理[Gray97]。
Conclusions and Future Work
新兴的应用程序,如数据挖掘、多媒体特征提取和近似搜索,涉及到巨大的数据集,在100个GB或TB的数量级上,证明了大量的活动磁盘是合理的。许多这些应用程序都有较小的CPU和内存需求,并且对于跨活动磁盘的执行很有吸引力。
为驱动器内部的应用程序代码提供一个安全的环境,以保护驱动器上数据的完整性和确保在行为不当的应用程序代码存在时具有适当的功能是至关重要的。随着计算变得更加分散,资源管理的问题也变得更加复杂。活动磁盘将需要做出比现在的磁盘驱动器更复杂的调度决策,但它们也通过利用它们提供的更丰富的接口,打开了许多新的优化领域。
 微信
微信 支付宝
支付宝

