
AC-Key——Adaptive Caching for LSM-based Key-Value Stores
本文由明尼苏达大学Fenggang Wu等人于2020发表于ATC。作者结合LSM-Tree的结构特点在ARC(Adaptive Replacement Cache)的基础上提出了基于缓存效率因子的E-ARC,并通过HAC对不同类型的缓存对向进行层次化管理。作者提出的分层自适应缓存算法可以动态感知负载中key-value cache、key-pointer cache以及block cache的变化,根据负载变化对缓存大小进行动态调整。
Background
由于LSM-Tree本身的结构特点,在读取操作时会伴随严重的读放大问题。解决上述问题的主要方法是使用cache,但是LSM的分层结构使得人们很难搞清楚cache一个entry所带来的开销和好处。同时为了在点查和范围查询取得平衡,cache的设计变得更为复杂。AC-Key将三种类型的cache:key-value cache,key-pointer cache,block cache整合进一个系统,并且可以根据负载自动调整三者比例。AC-Key使用了一个新的方法来衡量cache所带来的开销和收益。AC-Key是基于RocksDB实现的。从收益的角度看:不同层的Key-Value pair被cache到的收益是不一样的,cache层数越深的记录节省的IO开销越多。从开销的角度看:根据KV的大小,cache对内存的占用也不一样。点查和范围查询这两种操作对cache的要求并不一样。
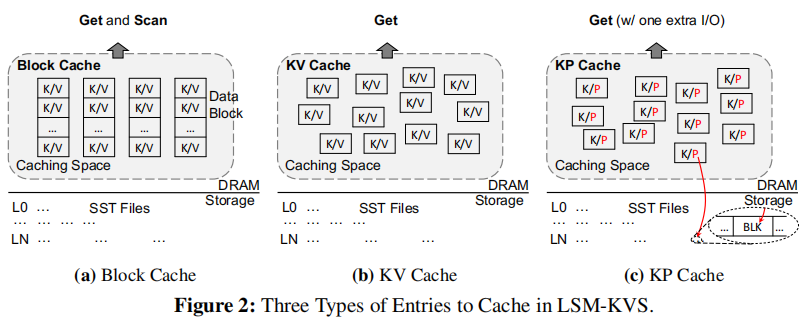
其中key-value类型的缓存适合点查询,key-pointer类型的缓存适合value特别大的数据,此时可以只记录一个指向value所在block的指针
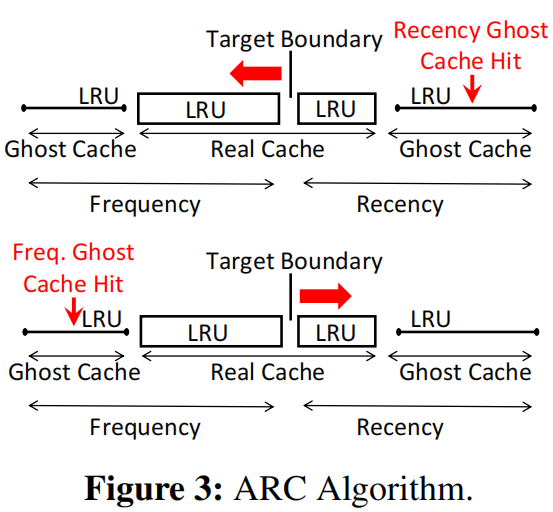
ARC用于DRAM中的Page替换。总体来说,ARC将cache分为两部分,一部分为新进cache(recency-cache,类似JVM的新生代),另一部分为频率cache(frequency-cache, 类似JVM的老生代)。这两部分分别是一个LRU实例。ARC的策略是,当一个数据第一次被访问的时候,它首先被缓冲到recency-cache中,当该数据再次被访问的时候,它会被迁移到frequency-cache中。
关于缓存中应该存放哪些数据,作者总结了四条规律:
- 应该将缓存key-value以及key-pointer的优点结合起来以更好的优化点查询;
- KV缓存和KP缓存有利于点查询,但是不利于范围查询,Block cache对点查询和范围查询都有利但是空间利用率低;
- 缓存算法应该考虑缓存不同条目占用的DRAM空间以及可以节省的I/O数量;
- 缓存算法应该对不同的工作负载进行动态调整;
AC-Key Design
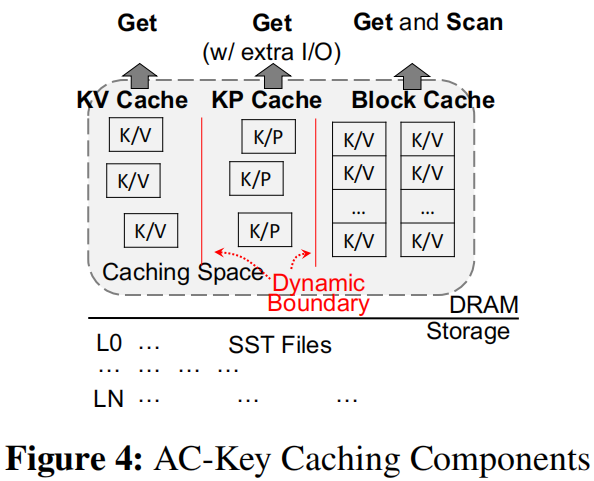
AC-key由KV cache、KP cache以及Block cache组成,内部的替换策略使用作者提出的基于LRU改进的E-LRU算法。其中Block cache由Data Bock、Index Block以及Bloom Filter Block组成,整体结构如上图所示。对于数据访问,如果数据条目被第一次访问将被放在KP cache中,AC-key认为这个条目是预热条目(warm entry)。如果该条目在KP cache中被再次访问,那么将其移动到KV cache中,此时系统认为该数据条目为热条目(hot entry)。如果上边第一次被访问的数据value大小小于一个pointer的大小那么将其放入KV cache中更加划算。
get 操作:查询首先会查询memtable,如果命中则返回,如果没有查询KV cache命中则返回。未命中KV cahce但命中KP cache则在Block cache中查找是否存在对应的Block,如果没有则先将对应的Block读入Block cache,在Block内部如果找value则将其移入KV cache。若KV cache和KP cache都未命中,则在磁盘寻找对应的数据条目并将其移入KP cache。
Flush操作:如果memtable中存在比cache中更新的数据,AC-key在flush操作时会更新cache中的操作。
Compaction 操作:合并操作会导致部分KP cache和Block cache失效,由于合并操作需要在内存中计算新生成的block,所以可以将KP cache更新指向包含对应key的新Block,对于失效的Block,挑选与其overlapping最大的Block进行替换。
为了量化不同缓存的收益,AC-key引入了缓存效率因子caching efficiency factor并用此改进LRU以及ARC。缓存效率因子$E=\frac{b}{s}$其中b是缓存该条目可以节省的IO次数,s为缓存该条目占用的缓存空间大小,一般以字节为单位。其中m为get一个key所需查找的SStable个数的函数,$f(m)$代表找到一个key需要的IO次数,$f(m)$函数取决于LSM-tree的具体实现,一般需要读取m个SStable的Bloom filter Block,最后再读一次Index Block以及Data Block,所以一般$f(m)=m+2$。其余公式如下:
E-LRU:
传统的LRU在缓存替换时会选择最久未用的一个条目。E-LRU会选择最久未用的a个条目并淘汰其中缓存效率因子最小的条目。其中$a=e^v$,v通过计算从cache中采样得到的样本标准差得到。
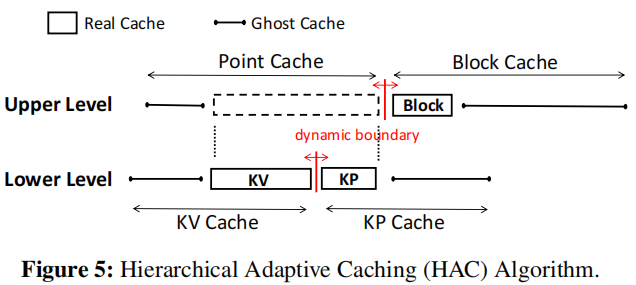
HAC:
一种可以分层调节各区域缓存大小的算法,AC-key缓存共分两层结构如下图,其中real cache存储真正的数据,ghost cache记录已被淘汰条目的元数据,占用空间相对较小。如果一边的ghost cache被命中就会增加自己real cache的容量。
E-ARC:
在Lower level中,单次调整长度为$\delta=kE=k\frac{b}{s}$,k用户可配置。
命中Real Cache:如果命中KV Cache就将entry往MRU一边调整。如果命中KP Cache就将entry移到KV Cache中。
命中KV Ghost Cache:把boundary往KP Cache移动。从storage读出entry后,将entry放入KV Cache的MRU端。
命中KP Ghost Cache:把boundary往KV Cache移动。从storage读出entry后,将entry放入KV Cache的MRU端。
未命中Cache:从storage读出entry后,将entry放入KP Cache。
在Upper Level中,Upper Level的boundary单次调整长度: $Δ=kE$
- entry淘汰后会记录在Upper Level的Ghost Point Cache,以及Lower Level的Ghost KV Cache或Ghost KP Cache。即会记录两次
- Block Cache淘汰掉的Block会记录在Ghost Block Cache
- 如果Ghost Point Cache被命中,Lower Level的boundary会先调整,然后Upper Level的boundary再调整。
Point Cache的变化会按如下公式分配给KP Cache和KV Cache
为 的大小, 为 $K P C a c h e$ 的大小
- ghost cache只是为了记录对应的key是否存在,那么可以利用hash来节省存储空间
- 使用一个4Byte的哈希签名代替key存入Ghost Cache,但是因为碰撞会出现假阳性的问题
- 如果entry很多时Ghost Cache依然会占用大量的空间,所以当cache命中率波动小于阈值Θ(默认为5%)则会关闭Ghost Cache,释放空间给Real Cache。当波动大于阈值Θ时重新开启Ghost Cache
Evaluation
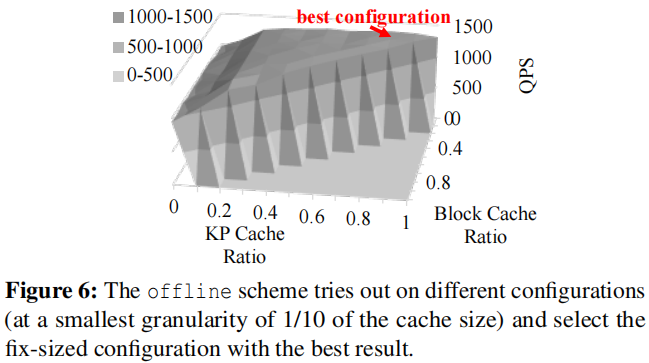
AC-key基于RocksDB实现,实验设置了对照组为:AC-Key、rocksdb:默认配置,即只有Block Cache、pure-kv:只使用KV Cache、pure-kp:只使用KP Cache、offline:使用固定大小的KV Cache、KP Cache、Block Cache,三者比例为如下实验得出的最优配置。
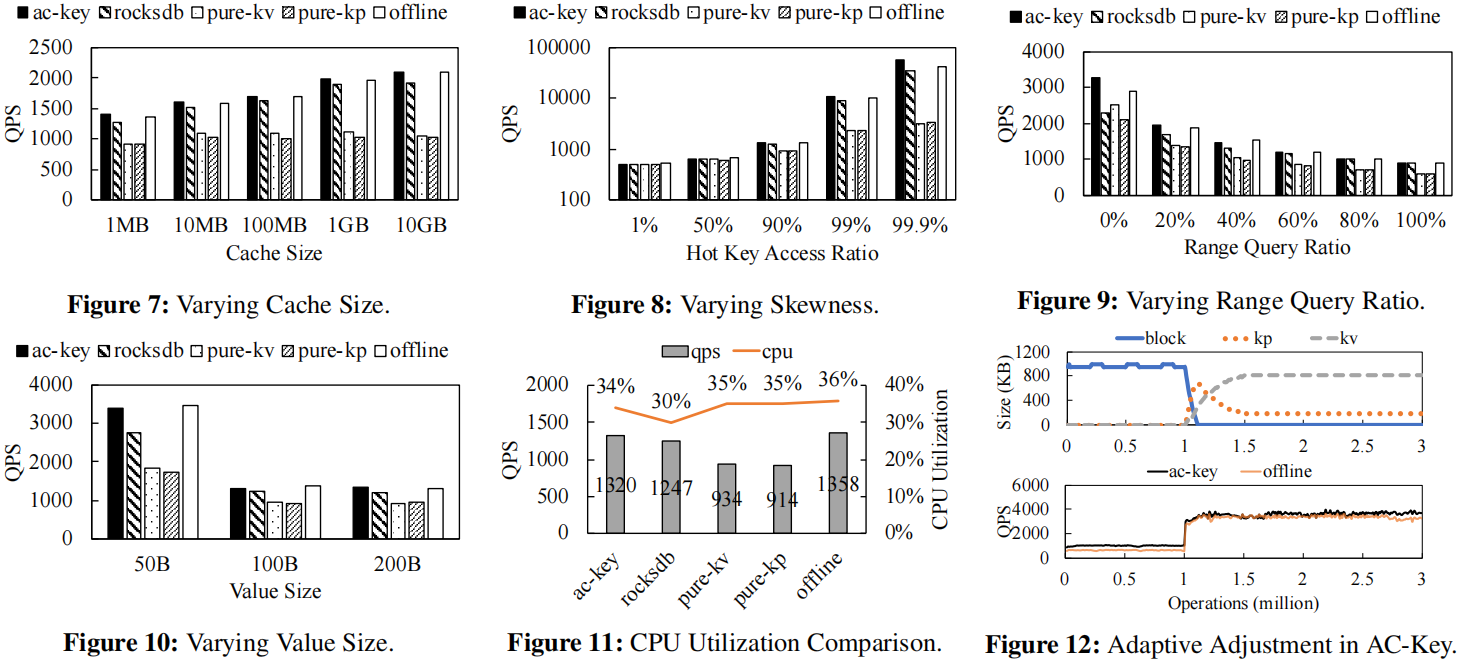
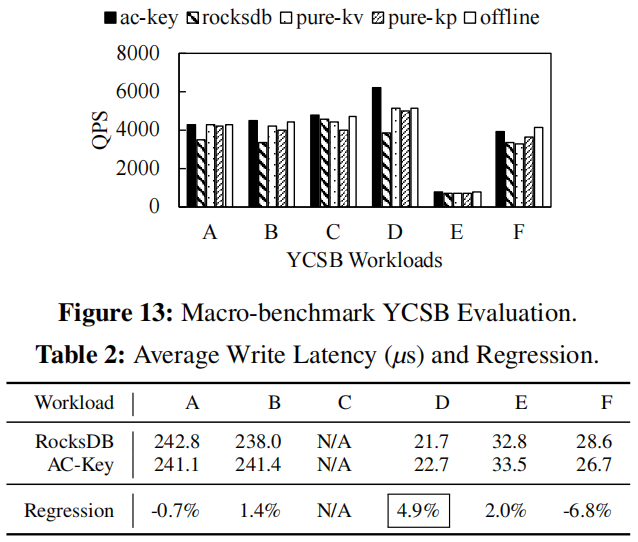
实验结果表明,热点越是集中AC-Key的优势越是明显,AC-Key对点查性能的提升明显,在value较小时优势明显,与offline差距很小。绝大部分情况下只有Block Cache的rocksdb比pure-kv或pure-kp要好不少,而且没有和AC-Key拉开太大差距,可能Block Cache还是重要的多。下图为在YCSB上的实验结果,在D工作负载上AC-key相较于RocksDB提升最多。
Conclusion
AC-key针对LSM-tree的结构特点引入缓存效率因子改进LRU以及ARC使其可以根据负载动态调整每个缓存组件的大小,实验结果表明不同负载下AC-key相较于RocksDB有较好提升。但是实验部分感觉只有QPS指标,对空间利用率,缓存命中率,查询延迟等指标没有提及,此外LSM-tree本身就有冷热数据,最底层的数据倾向于冷数据,但是将其缓存到内存中缓存效率因子较高,是否可以增加一个松弛项$\frac{1}{l}$或者其他办法将层数对数据冷热程度的反应体现出来。
 微信
微信 支付宝
支付宝


