
TridentKV A Read-Optimized LSM-Tree Based KV Store via Adaptive Indexing and Space-Effificient Partitioning
本文是华中科技大学Kai Lu发表在TPDS(2022)上的一篇关于LSM-tree索引优化的期刊论文。现有的索引策略限制了KVS的读性能,基于LSM-tree的KVS采用插入墓碑的删除机制,当存在大范围数据删除时,读操作具有较大的性能波动。本文提出的TridentKV旨在优化KVS的读性能,其核心包括动态变化的可学习索引结构、空间高效的分区策略、支持异步读操作以及SPDK。TridentKV基于RocksDB构建,在不丢失写性能的基础上读性能提升了7x ~ 12x,利用TridentKV替换RocksDB存储Ceph中的元数据可使Ceph的读性能提升20%~60%。
Background and Motivation
众多持久化KV存储采用LSM-tree作为索引结构来实现较高的写性能与可扩展性,但由于LSM-tree的多层结构,读操作需要遍历各层,这将造成严重的读放大以及读性能损耗。近年来众多工业界学术界工作尝试从filter、cache、index structure优化基于LSM-tree的KVS的读性能。RocksDB使用Bloom过滤器来减少额外的I/O、通过数据块哈希索引优化点查询、保存相邻层级的键值范围信息减少搜索次数、构建前缀布隆过滤器加速scan、支持元数据的优先级缓存减少随机读操作的I/O。虽然RocksDB已经对读性能进行了优化,在现代高带宽低延迟存储设备下仍然存在问题:(1)低效的文件索引严重影响了存储设备的读取性能,特别是高速存储设备(2)当进行大规模删除时,读取性能会严重下降(Read-After-Delete问题)。TridentKV针对上述两个问题进行了优化。
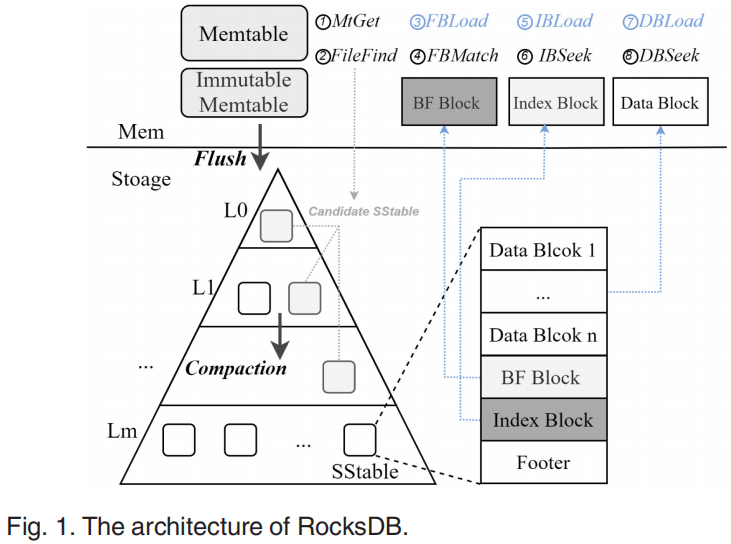
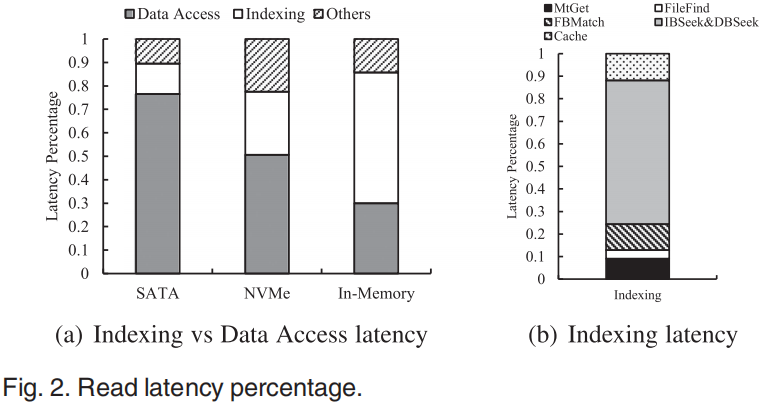
RocksDB中的读操作如下图所示,查找特定key涉及的步骤可以分为两类:in-memory indexing(MtGet, FileFind, FBMatch、IBSeek、DBSeek)以及data-access(FBLoad,、IBLoad、DBLoad)。图2可见不同设备下RocksDB查询延迟中各个操作的时间占用,随着存储设备越来越先进,数据访问占比越来越低、索引操作占比越来越高。而在索引中,IBSeek(在Index Block中查找对应的Data Block)以及DBSeek(在Data Block中查找对应的key)占比最高。
 |
 |
|---|---|
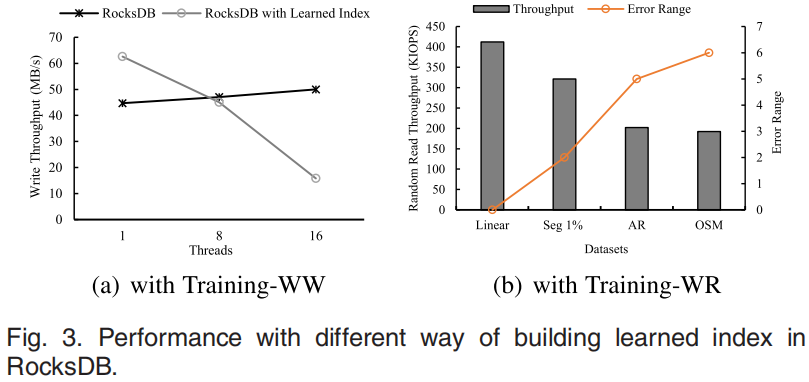
BourBon以及Google提出的可学习索引是与本文相关的两个工作,BourBon的可学习索引在读操作时建立(Training-WR),Google提出的方案中可学习索引在写操作时建立(Training-WW)。但是Training-WR对于读重的工作负载表现不佳,Training-WW在写重的工作负载中表现不佳,如图3b所示。
 |
 |
|---|---|
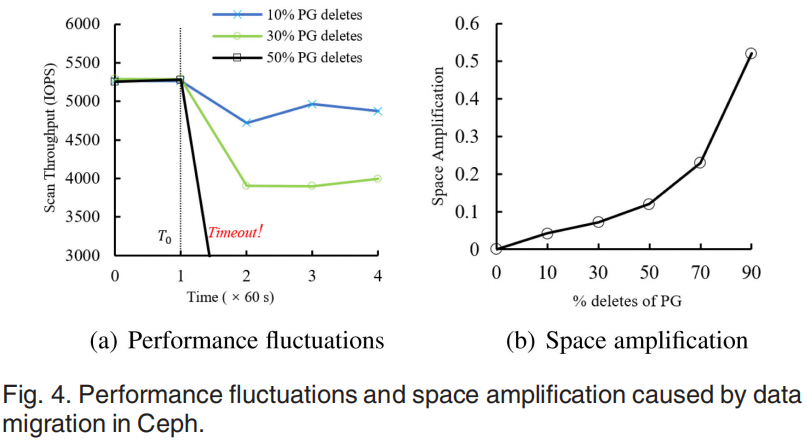
此外,Index deletion和Data migration会引发大范围的删除操作,图4评估了不同尺度的数据迁移引起的扫描性能波动和空间放大问题。RocksDB为了避免数据迁移采用了标记删除法,删除操作插入一个墓碑来使旧数据失效,然而在大量数据删除情况下插入过多的墓碑会影响读性能尤其是scan,以及造成严重的空间放大。现有的解决方法有:定期调用合并操作合并已删除的数据(会降低系统性能)、以固定方式组织被删除数据(数据重组织代价高昂)。综上可得到两个挑战:
- 如何更好地利用学习索引来优化基于LSM-tree的KVS文件索引;
- 如何更好地解决基于LSM-tree的KVS的Read-After-Delete问题;
TridentKV Design
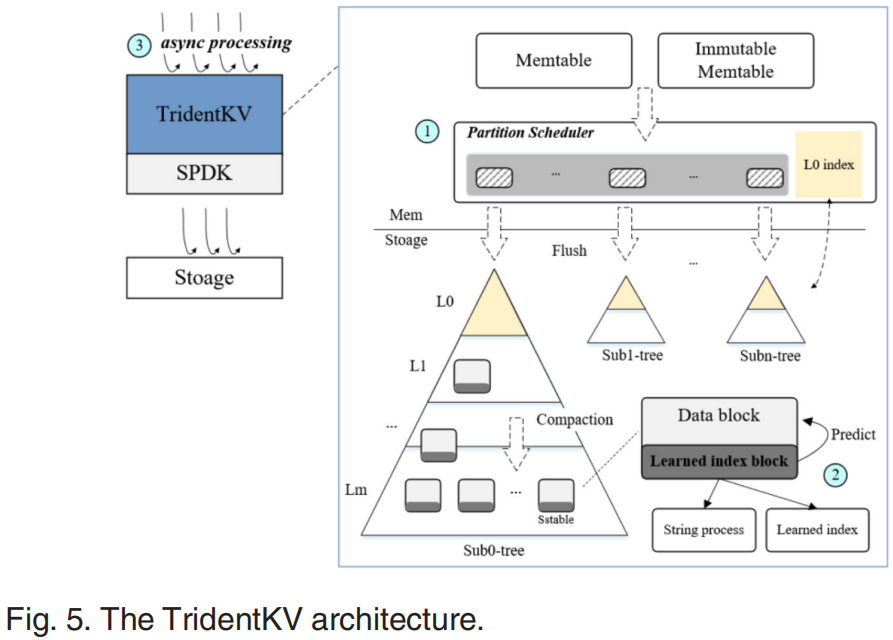
为了解决上述两个挑战TridentKV采用了学习索引和分区存储,总体结构如图5。(1)TridentKV采用分区存储,数据根据一定标准(键值范围、二级索引等)被存储在不同的子树中,每个子树都是一个磁盘上的LSM-tree。和RocksDB一样内存结构是memtable和immutable,但是当讲memtable刷入磁盘时,TridentKV会先将kv对通过分区调度器存储buffers中,然后再分别将每个buffer刷入磁盘。分区调度器由buffer和轻量级L0缓存组成,所有的分区共享一个memtable以减少开销。(2)TridentKV将SStable中的Index Block换成了Learned Index Block来提升SStable的查询性能,学习索引块由字符串处理区(将string转为整型数方便模型训练)和学习索引(两层结构)组成。Learned Index Block比Index Block小得多,可以放下更多数据。(3)TridentKV通过SPDK接口管理底层的NVMe SSD,避免Linux I/O 栈的性能开销,并为上下游提供异构IO。(4)查找一个key TridentKV首先依次搜索内存中的memtable、immutable、分区调度器,如果没找到将通过map搜索对应子树中的SStable。
Adaptive Learned Index
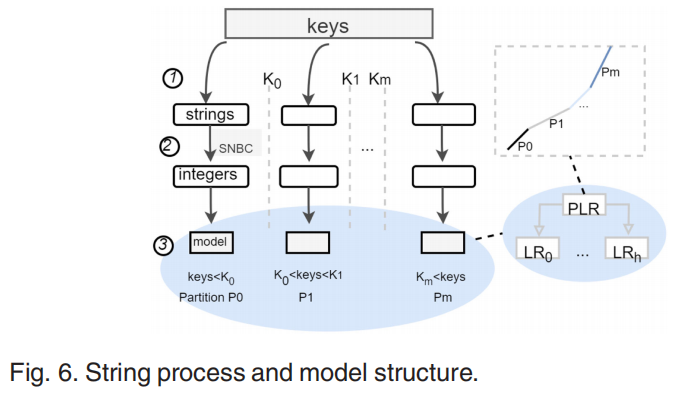
对于字符串的处理,TridentKV基本采用了Google提出的SNBC(string number base coding)方法,先将字符串转化为数字,但是考虑到同一分区中会存在较大的gap,TridentKV在将字符串转化为数字后进一步将其分为p0、p1、…pm个分区,方便高效编码。训练采用贪婪方法,分为三步。首先将key分入一个组,其次利用SNBC将其转化为数字,然后在相同组中进行训练,训练过程中需满足约束$(E_t, Max_t)$,两个参数为模型误差和key最大值。如果加入的key破坏了约束将被移除当前组。模型结构如下,是两层结构。第一层为PLR分段线性回归。当SBNC编码结束,每个分区的数字将被指派给PLR中对应的分段。第二层由多个线性回归LR组成,需要注意如果采用training-WW方式,模型需是单调的。
 |
 |
|---|---|
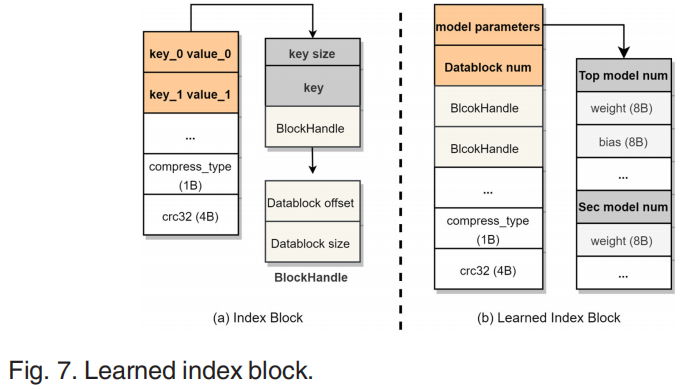
TridentKV采用动态模型学习方法,在之前提到的Training-WR和Training-WW之间进行trade-off,伪代码如下。训练策略为(1)在写密集场景下Training-WW应该被避免,否则将造成严重的性能丢失;(2)在非写密集场景下,优先使用Training-WR;(3)如果Training-WW不可用,可在读操作期间使用Training-WR;(4)如果Training-WR无法保证低错误率也不会被采用;Learned Index Block内部结构如上图所示,相较于传统的Index Block没有保存key,学习索引块主要分为两部分,一个是模型参数,一个是块句柄(包含块的offset和大小)。学习索引块大小更小,可以存放更多信息加速查询操作。

Partition Scheduler
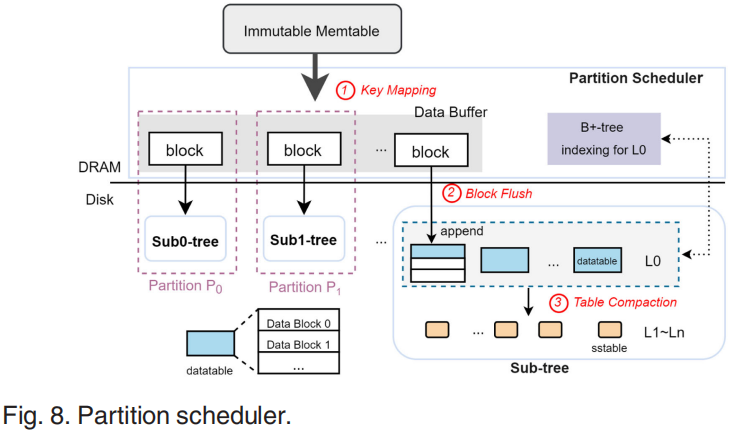
为解决Read-After-Delete问题引入了分区调度器。TridentKV将被删除的key分配到相同的区域,范围删除可以直接删除对应区域的数据。RocksDB的CF分区每个分区有一个memtable,相比之下TridentKV只有一个memtable、两个buffer arrays、一个轻量级L0缓存索引结构。Data buffer由写缓存和flush缓存构成,为了维护block中数据的有序性,每个immutable首先被加入写缓存,然后写缓存会被合并到flush缓存中。合并过程中每个分区都保持key有序,如果一个分区的flush缓存满了将触发flush操作。TridentKV以Block执行flush操作,block组成datatable,数据block将被刷到对应子树的L0中。B+树索引的构建与SLM-DB类似。
 |
 |
|---|---|
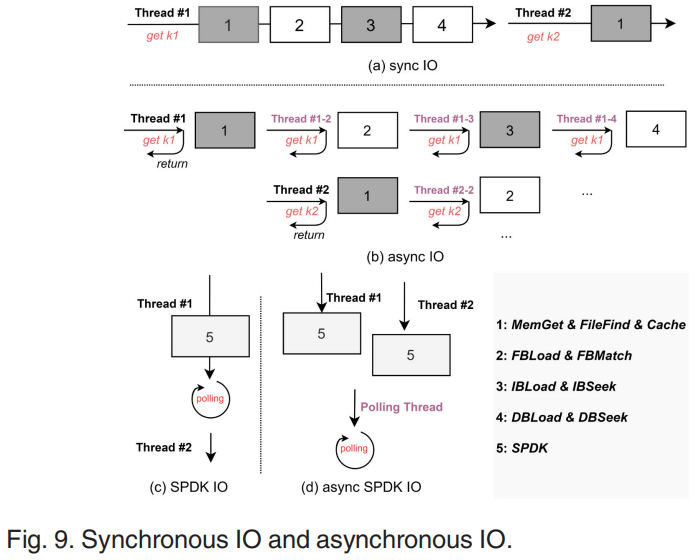
SPDK and Asynchronous Read
异步IO与流水线类似,在同步读中(图9a),必须等待thread#1完全完成K1的搜索,对K2的搜索才能进行。对于异步IO,一旦搜索的第一阶段完成,子线程#1-2将开始后续阶段。一旦线程#1异步返回,线程#2就开始搜索k2。目前,TridentKV只实现了点读取的异步转换。使用异步IO和使用SPDK,一个单独的线程(在图中称为轮询线程)用于轮询,而原始的IO线程直接异步返回。这就大大减少了由轮询引起的延迟。
Evaluation
软硬件配置:
- RocksDB (V5.4.0)、Ceph (v12.2.13)、MKL (Math Kernel Library) library、plug-ins style Implementation;
- Intel Skylake Xeon Processor (2.40 GHz) 54 GB memory、Centos 7 kernel of 64-bit Linux 3.10.0;
- Intel DC NVMe SSD (P4510, 2 TB);
- Samsung SATA SSD (PM883, 3.84 TB)、Seagate Exos 7E2 3.5 HDD (2 TB);
实验评估旨在回答以下几个问题:
- TridentKV性能优势如何;
- TridentKV引入的三个technique对系统性能有何影响;
- TridentKV在Ceph中的性能优势如何;
- TridentKV对Read-After-Delete问题缓解程度如何;
Bench Performance
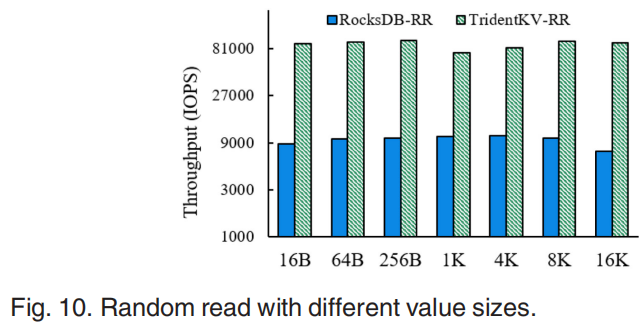
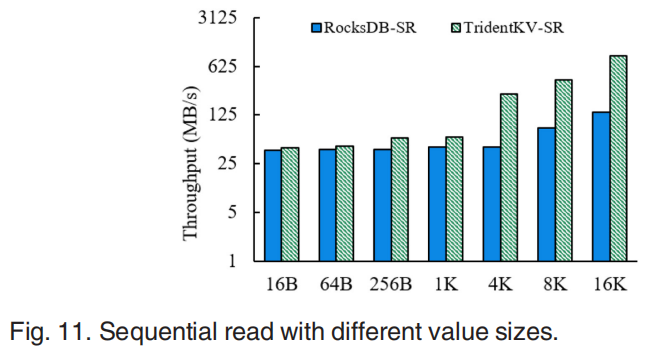
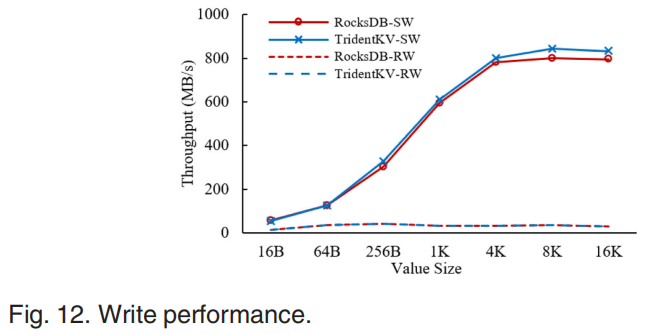
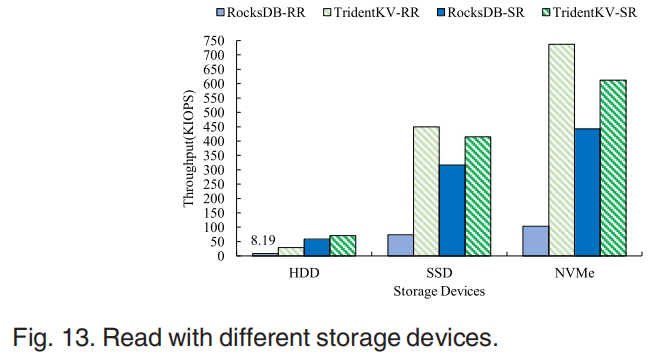
TridentKV可以明显提升随机读性能。在value较大时对顺序读的性能提升较大,但没有随机读明显。因为RocksDB采用了基于迭代器的方式实现顺序读,属于key的Block被放入内存加速了顺序读。当value较大时提供的异步IO展现出高效性。同时写性能差距不大。在不同设备上的测试表明在NVMe SSD上TridentKV可以实现更高的性能提升因为在慢速设备上的延迟主要来自data access,学习索引以及异步IO在快速设备上更有效,且只有NVMe设备上支持SPDK。
 |
 |
|---|---|
 |
 |
|---|---|
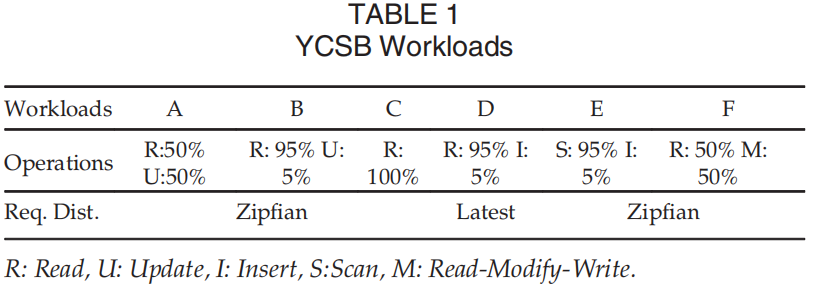
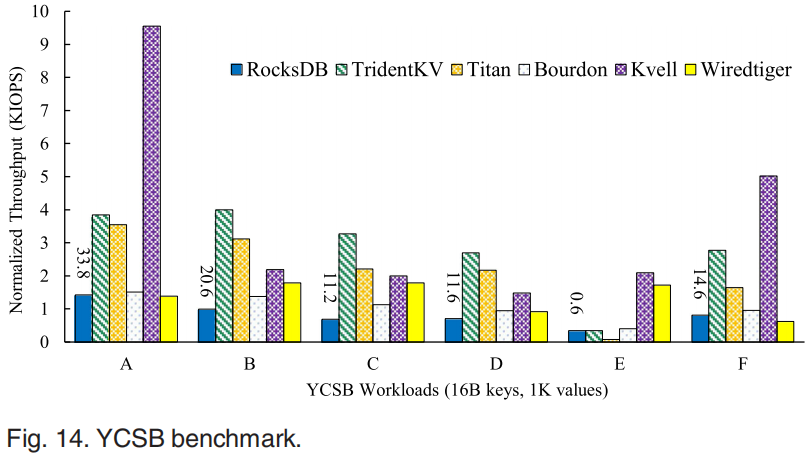
在YCSB上对各个KVS进行测试,除工作负载E外,TridentKV在所有工作负载上的性能都比RocksDB高出2.6到5倍。对于scan intensive负载E不是异步读,学习索引没有提升scan性能。
The Impact of the Three Techniques
对于各种负载的读取操作,异步IO为一个小的高速缓存带来了最大的性能改进。对于一个较大的高速缓存,大部分的负载不需要访问磁盘,而学习到的索引对性能的影响最大。
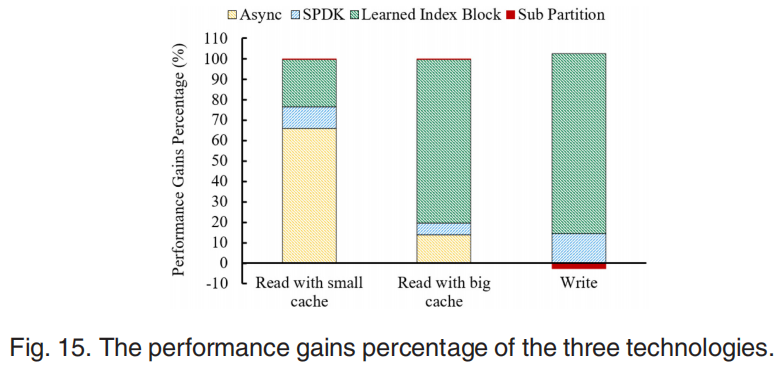
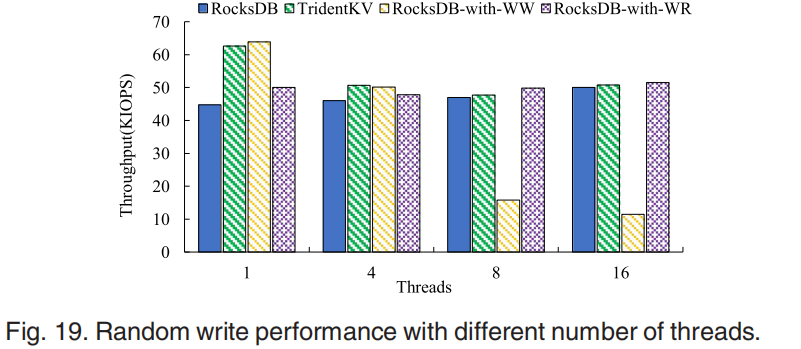
图19显示了在AR工作负载下的写入性能:
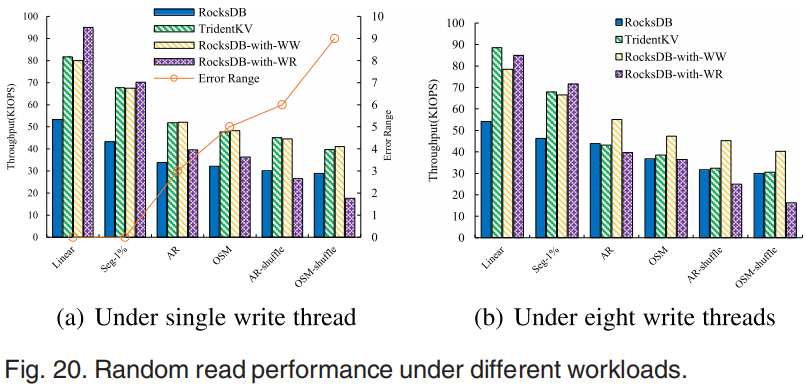
不同工作负载的读取性能变化如图20所示,其中图20a为使用一个线程进行写操作后的读取性能,图20b为8个线程。模型在不同工作负载下的误差范围为0~9。如图20a所示,RocksDB-with-WW的性能不受误差范围的影响,并且得到了很大的改进。TridentKV采用单线程写操作后的训练-WW方式,其性能与RocksDB-with-WW相似。对于Training-WR方法,随机读取性能随着误差范围的增加而严重下降
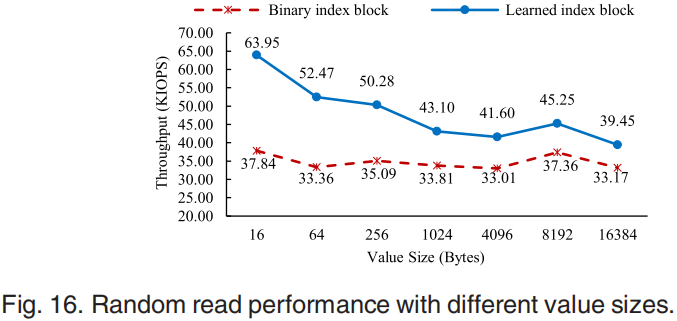
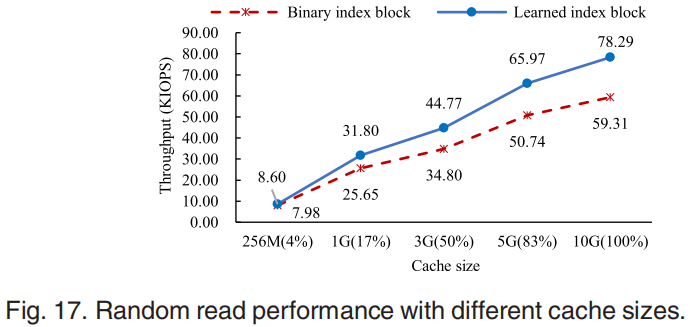
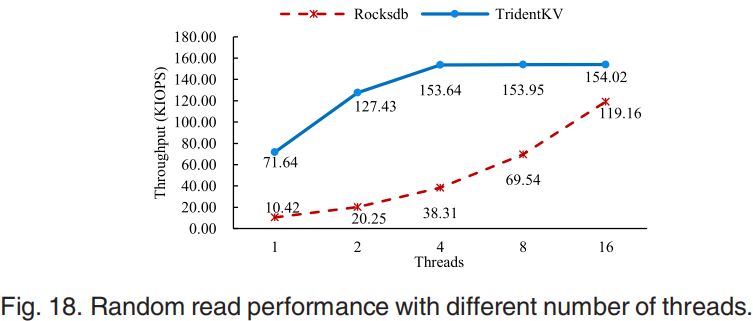
第二组是分析学习到的索引比传统的二进制搜索索引的优势,使用db_bench得到的结果如图16-17所示。对于图16 value较小的情况,data block中的数据更多,普通二分查找需要的时间越多,但是学习索引没有这个问题,所以学习索引可以实现更多的性能提升。对于图17缓存大小越大,学习索引性能提升越多,因为学习索引block比普通索引block小的多,cache越大可以存放更多的学习索引。图18中异步IO随着线程数增加性能增加,但是以CPU占用为代价最终会遇到CPU资源限制。
 |
 |
 |
|---|---|---|
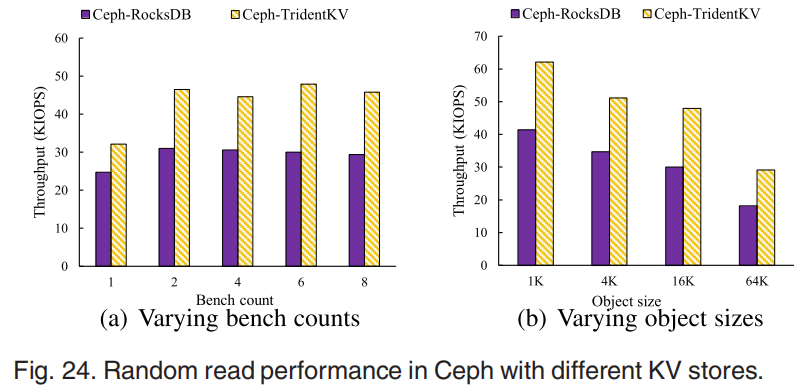
图24展示了在极端随机读负载下Ceph利用TridentKV实现了大约50%的性能提升。
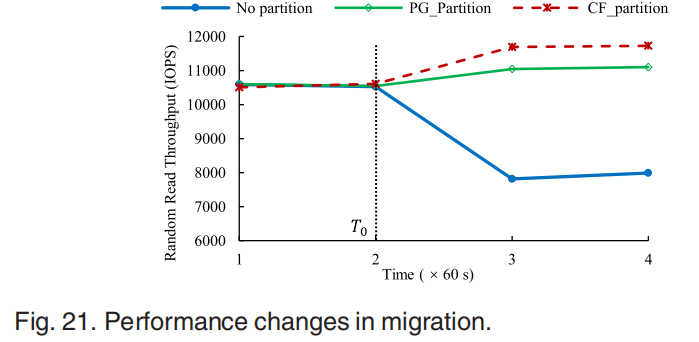
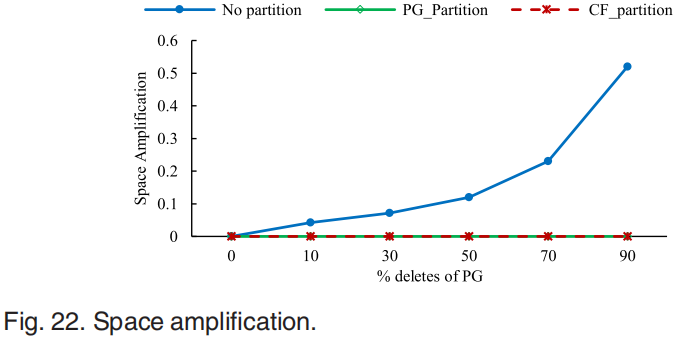
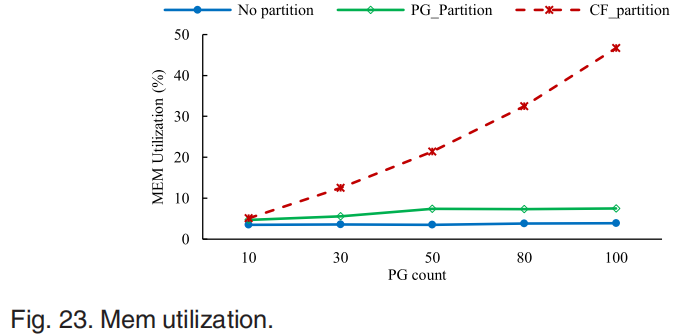
对于Read-After-Delete问题,第一组比较了在数据迁移前后由于不同的分区策略而引起的性能变化。非分区策略下的性能下降很明显,主要是由标记删除造成的。另外两种分区策略的性能不受删除后的影响,删除后的性能提高是因为数据量减少了。图22展示了非分区策略导致的空间放大问题。图23显示了随着placement group增加系统的内存占用变化。因此,可以得出结论,PG分区可以保证其性能不受Ceph数据迁移的影响,并且不占用太多的内存。
 |
 |
 |
|---|---|---|
Conclusion
读性能优化:
LSM-tree的多层结构牺牲了其读性能,现有的优化方向有:Filter Optimization(BLSM、ElasticBF、SuRF)、Auxiliary Index Structure(SLM-DB、 Kvell、Bourbon)、Cache Optimization(Ac-Key、 LSBM)。TridentKV将学习到的索引,而不是将额外的内存索引结构集成到SStable中,以减少内存开销。
分区存储:
由于实际工作负载的高空间局部性,分区存储可以有效降低合并成本。RocksDB CF分区、EvenDB、Rmix、Ceph(PG分区 解决Read-After-Delete问题)。
学习索引:
ALEX、 XIndex(提升学习索引的写性能和并发度)、Sindex(支持string),TridentKV首次将学习到的指标应用于Rocksdb,改进了模型的构建方法。此外,它还将学习到的索引集成到一个块中,并很好地支持字符串键。
 微信
微信 支付宝
支付宝

