
SILK Preventing Latency Spikes in Log-Structured Merge Key-Value Stores
源码:https://github.com/theoanab/SILK-USENIXATC2019
由悉尼大学Oana Balmau等人2019年在ATC发表,旨在对LSM KVs的长尾延迟进行优化。论文首先通过在RocksDB上的实验表明长尾延迟问题确实存在以及潜在的原因,然后分析了业界针对长尾延迟的解决方案,最后提出了SILK解决方法并在YCSB以及Nutanix工作负载下进行性能验证。
Background
KV存储支持用户操作和内部操作,其中用户操作Get()、Update()、Scan()用来存储和遍历数据,内部操作包括flushing和compaction。更新操作在内存中进行以获得更好性能,flush操作将内存中的数据持久化到磁盘,compaction操作将LSM-tree的低层数据合并到高层。论文表示在现有的LSM KVs中当面对繁重多变的客户端写负载时长尾延迟问题仍然存在。
现有工作通过减少内部操作开销来提升客户端吞吐量,但是内部操作仍是必要的,由于对这些内部任务的干扰,在正在进行的内部操作期间到达的客户端操作会增加延迟。实际应用中限制内部操作分配到的IO带宽是常见的手段,但当客户端存在突发写请求,触发突发flush操作,当此时恰有众多compaction操作时flush将和compaction争用有限的IO带宽从而速度降低。这将导致内存中数据结构变满最终阻塞后续的写操作。此外,限制compaction速率也是不够的,考虑到LSM-tree底层结构被填满后将阻塞flush,最终阻塞客户端写操作。论文基于RocksDB构建了SILK,其中最重要的思想是I/O调度器:(1)在客户端操作和内部操作之间动态分配带宽 (2)优先考虑可能阻塞客户端操作的内部操作 (3)允许对不太重要的内部操作进行抢占;
LSM-Tree的基本结构就不再赘述,很多论文都有介绍。其中大多数的LSM KVs支持并行compaction操作(除了L0到L1,因为L0中SStable的key range存在重叠),compaction操作涉及磁盘数据读写涉及大量IO开销。系统维护一个内部 FIFO 工作队列,其中将flush和compaction排入队列。当一个新的内部工作请求入队时,它被放置在内部工作队列的末尾。当 Cm 填满时,flush将进入队列。flush操作或者compaction操作后compaction操作可能进入队列。内部工作线程池为内部工作队列中的请求提供服务。
长尾延迟现有业界解决方案
RocksDB:
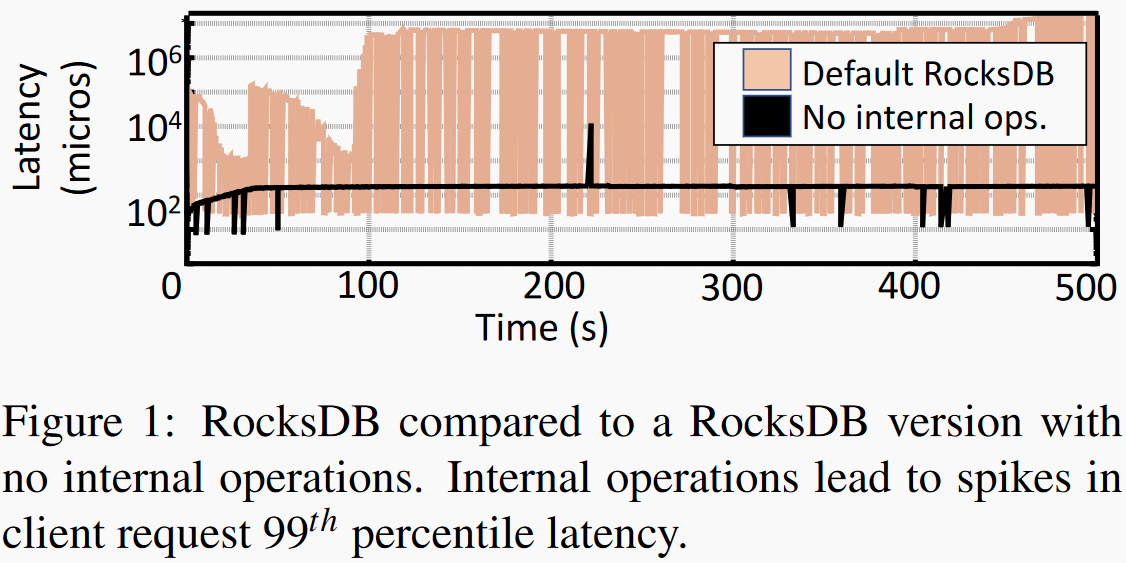
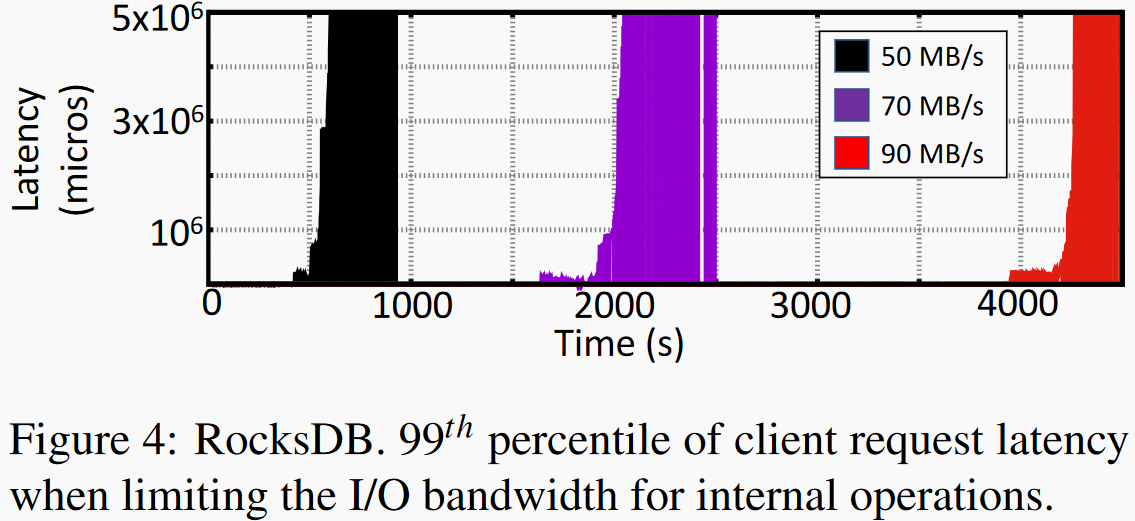
左图对比了RocksDB开启和关闭compaction操作时尾延迟情况,可以看到开启内部compaction操作长尾延迟比没开时高了四个数量级。右图显示利用RocksDB的rate limiter给内部操作限制不同的IO带宽,我们发现给内部操作分配更高带宽可以推迟较高长尾延迟发生时间,但随着数据量积累还是会有内部操作与上层操作争用带宽的情况发生,从而导致较高的尾延迟。
|
 |
|  |
|
| :—————————————————————————————: | :—————————————————————————————: |TRIAD:
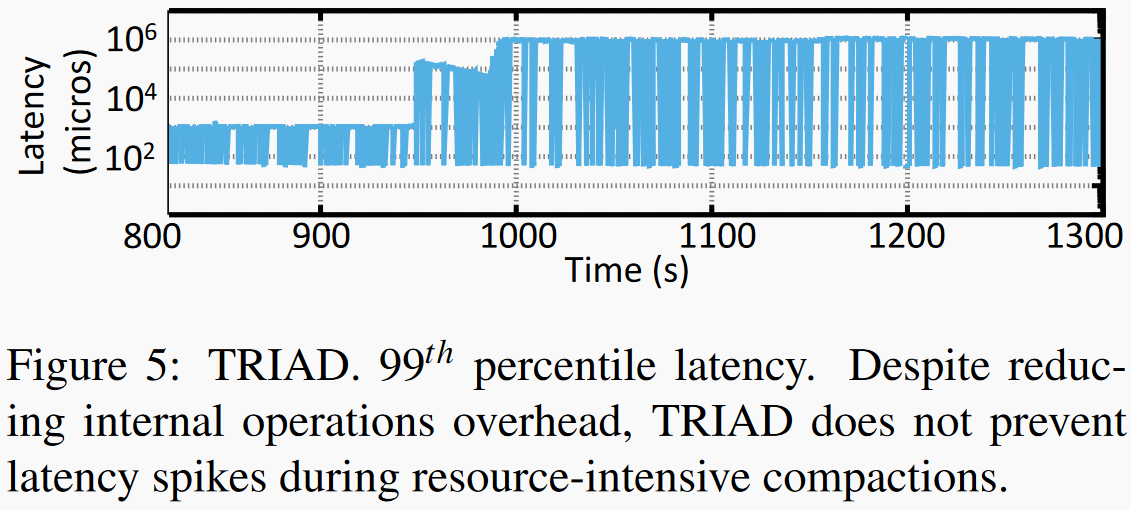
通过三个手段减小内部操作开销。将频繁更新的数据保存在内存中从而降低倾斜负载下内部操作的开销、利用log中已经写入的数据优化flush操作、采用基于开销的方式触发L0到L1的合并操作。这种方式会导致随着时间推移上层compaction增加,最终长尾延迟问题仍然存在。
PebblesDB:
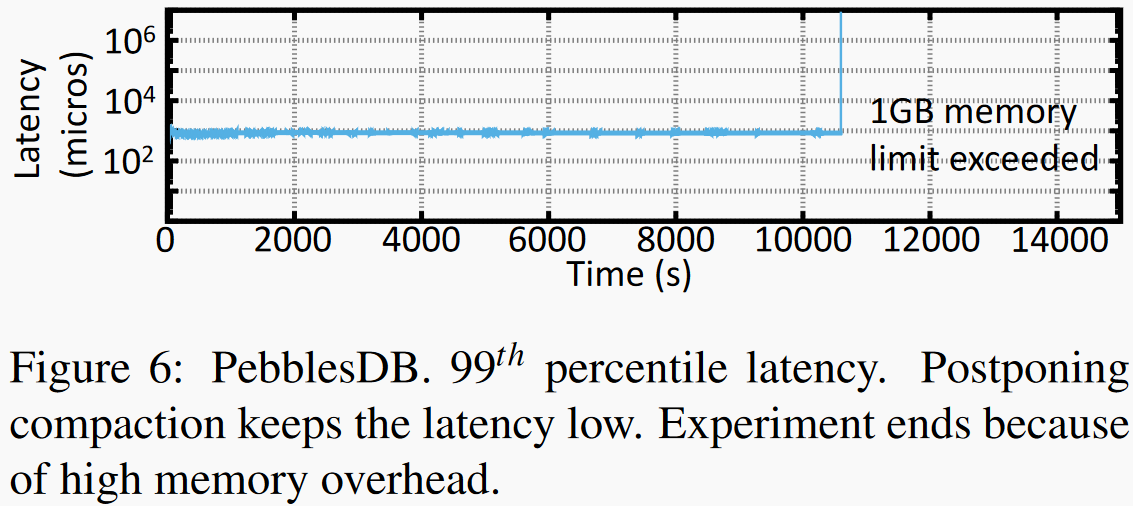
允许除了最高层外所有层存在key重叠,当内部guards数量积累到一定程度使触发对最高层的compaction操作,导致后期compaction操作大量抢占IO资源,整个客户端IO被阻塞直到compaction完成。
LSM KVs性能需求
- 低长尾延迟、与用户负载匹配的系统吞吐量、较小的内存占用;
LSM KV 中的一个常见问题是当客户端写入的突然爆发与长时间运行的资源密集型压缩任务并行发生时,LSM 内部工作和客户端操作之间存在干扰。尽管内部 LSM 操作直接影响客户端延迟,但是系统在处理内部操作时并没有考虑客户端负载。通过以上实验论文总结了三个lesson:
- 尾延迟主要原因为Cm写满导致写操作阻塞;
- 简单的限制内部操作带宽不能解决flush操作可用带宽受限问题,因为L0到L1的compaction操作优先级没有被保证;
- 选择性的进行compaction或者只在最高层进行compaction操作短期内可以避免写延迟,但是长期来看可能在某个时间点触发大量合并操作阻塞掉客户端IO;
Solutions
Opportunistically allocating I/O bandwidth to internal operations.
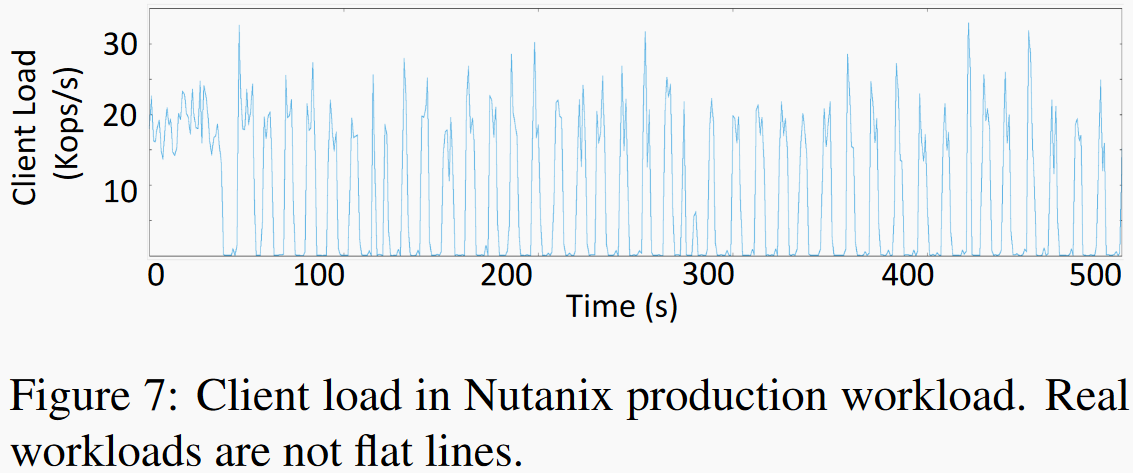
如图实际应用中,客户端负载是不断变化的。在客户端负载较高时,SILK为高层compaction分配更少的IO带宽并利用低负载阶段来处理内部操作的进行。动态的IO调节限制了内部操作和用户操作之间的干扰,同时也避免了内部工作长期积累导致的过载。
Prioritizing internal operations at the lower levels of the tree
SILK将LSM-tree内部操作分成三类:首先,SILK确保flush足够快,在内存中预留足够多的空间使得update操作得以继续。其次,赋予L0到L1的compaction第二优先级,保证L0不会出现写满,从而保证flush得以进行。
Preempting compactions
SILK 将 L1 以下级别的压缩放在第三位,因为虽然它们保持 LSM 树的结构,但它们的及时执行不会在短期内显着影响客户端操作延迟。
Implementation
Opportunistically allocating I/O bandwidth
SILK动态监测用户操作使用的IO并将剩余可用IO带宽分配给内部操作。用户负载监控和速率限制通过一个单独的SILK线程操作,监控粒度取决于负载的波动频率,SILK使用的粒度是10ms。SILK测量用户端使用的带宽$B$/s,假设LSM KV可用带宽大小为$T B$/s,那么SILK将动态的将内部操作带宽调整为$I=T-C-\varepsilon B$ /s。SILK使用标准速率限制器来调整IO带宽,并为flush操作和L0到L1的compaction操作预留一个最小带宽。为了避免频繁改动Rate Limiter引入过多开销,SILK只在当前测量值和新测量值差距较大时改变Rate Limiter,论文设置阈值为10MB/s,如果阈值过低将导致频繁调整rate limiter。参数$\varepsilon$是为了处理客户端负载较小的波动,这些波动不足以使用rate limiter调整内部操作的带宽。
Opportunistically allocating I/O bandwidth
LSM KVs 内部工作是通过一个内部线程池处理的,SILK维护了两个内部工作线程池:一个用于高优先级的flush操作,一个用于低优先级的compaction操作。
Flushing:
flush操作也可以使用内部操作的IO带宽,flush带宽最小值要满足在mutable写满前将immutable写入磁盘。SILK实现了两个内存组件,一个flush线程,设置多个内存组件和flush线程可能有利于维持更长时间的客户端高负载。
L0 to L1 compaction:
如果L0到L1的compaction需要处理而compaction线程池中所有线程都在处理更高level的compaction,一个线程将被抢占分配给L0层的compaction使用,SILK采用随机挑选的方式选择被抢占的线程。L0层合并操作可能受到动态IO带宽限制,SILK可以将L0层合并操作暂时用高优先级线程处理,此时上文提高的最小分配带宽将由flush操作和L0层合并操作共享。
Higher-level compactions:
更高level的合并操作通过低优先级线程调度,SILK以单个合并操作或者整个线程池来暂停或者恢复合并操作。有可能L2层的合并操作由于被L0层合并操作抢占而失效,SILK直接将被抢占合并操作已执行的结果丢弃。以及在考虑多个线程并行compaction时线程的数量应该根据总的可用带宽数量和完成一次合并操作需要的带宽数量决定。目前SILK在低优先级线程池中控制分配给合并操作的总带宽,也可以按照compaction紧迫程度更细粒度的分配带宽。
Evaluation
在Nutanix和TRIAD中将SILK实现为RocksDB的扩展版本,主要在写密集负载下测试了SILK的尾延迟。
| Hardware | 20-core Intel Xeon, with two 10-core 2.8 GHz processors, 256 GB of RAM, and 960GB SSD Samsung 843T、run with 1GB of RAM using Linux control groups |
|---|---|
| Benchmark | compare the performance of RocksDBSILK and TRIAD-SILK to RocksDB, TRIAD, and a version of RocksDB that uses the auto-tuned rate limiter |
| Measurements | 负载生成器将请求放置在KV store的工作线程中,延迟在负载生成器端测量,包含排队时间以及处理时间。每秒测量99th尾延迟和吞吐量 |
| Dataset | 大概500G数据,tuple大小可变,数据集预先填充 |
| KV store configuration | 128MB memory component size and two memory components;LSM KV可用总带宽200MB/s; a thread pool of 4 threads for internal operations; 8线程用于客户端,8线程用户内部操作;没有考虑数据压缩和提交日志; |
Nutanix workload
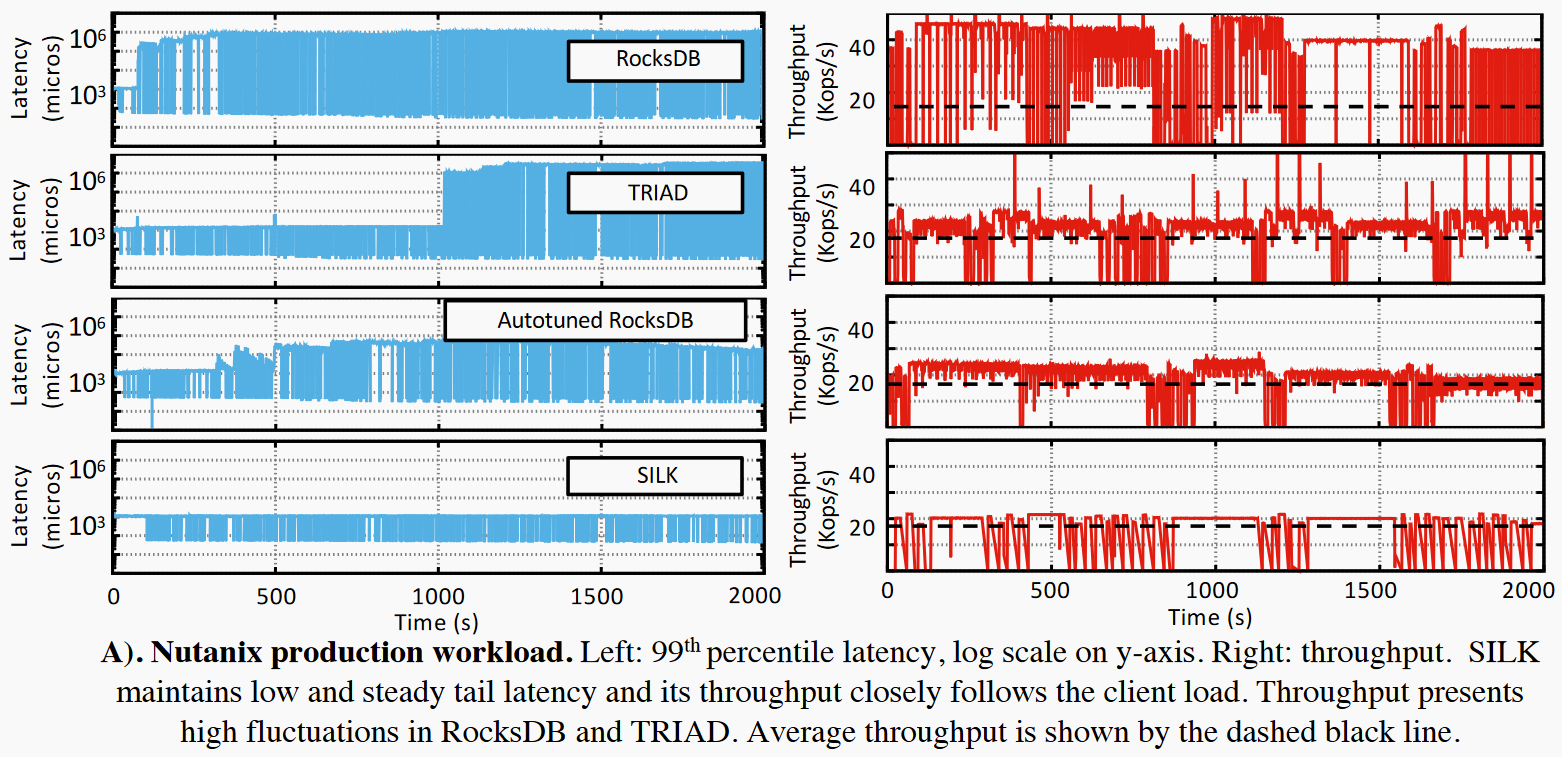
采样了Nutanix24小时工作负载,负载主要以写操作为主。上图展示了在该负载下SILK相较于其他系统的性能优势。左图显示SILK改善了尾延迟,右图黑色虚线为用户负载的吞吐,SILK的工作负载更加接近用户负载而RocksDB存在较大波动。
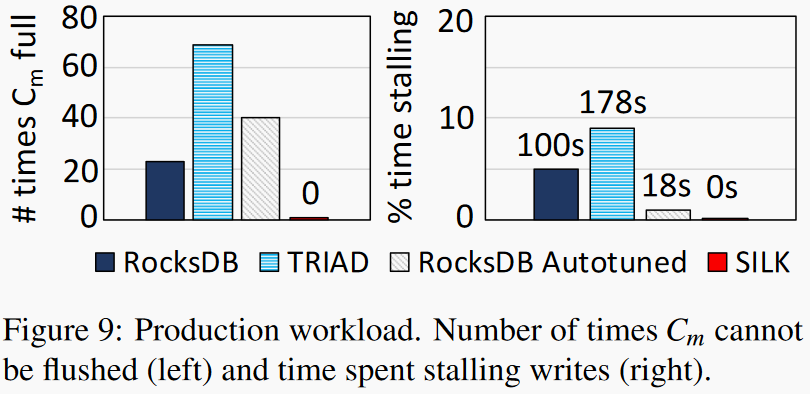
上图可见SILK中内存组件flush到磁盘的操作不会被阻塞,SILK不会阻塞write操作,当内存组件写满时总能够将其flush到disk中。
 |
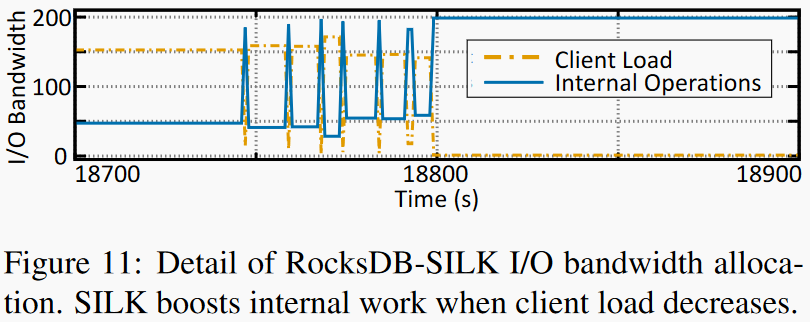 |
|---|---|
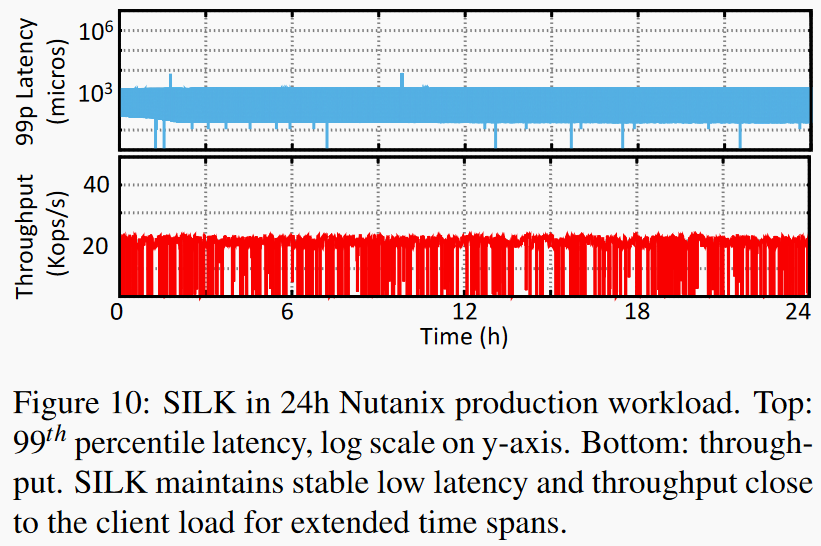
上图中SILK在Nutanix24小时工作负载下的长尾延迟和吞吐数据都很平稳,右图分析了IO带宽的分配情况。
YCSB benchmarks
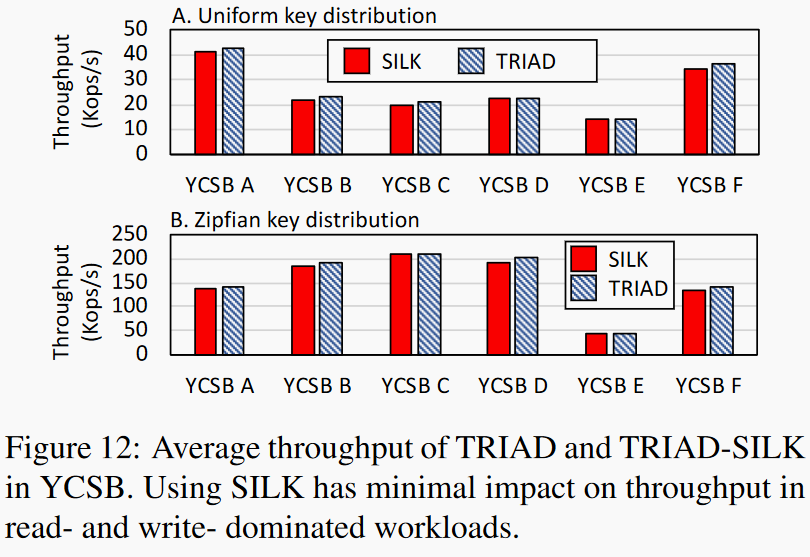 |
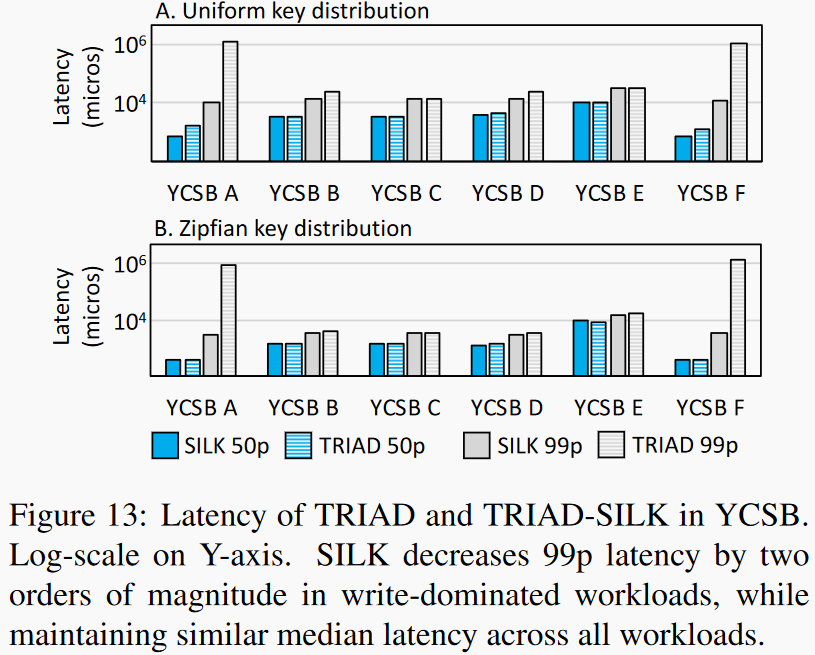 |
|---|---|
在YCSB六个工作负载上测试SILK性能。在uniform和zipfian两种负载分布下SILK对吞吐量影响都很小。右图显示在写密集负载下SILK对长尾延迟的优化更加明显。
Stress testing for long peaks
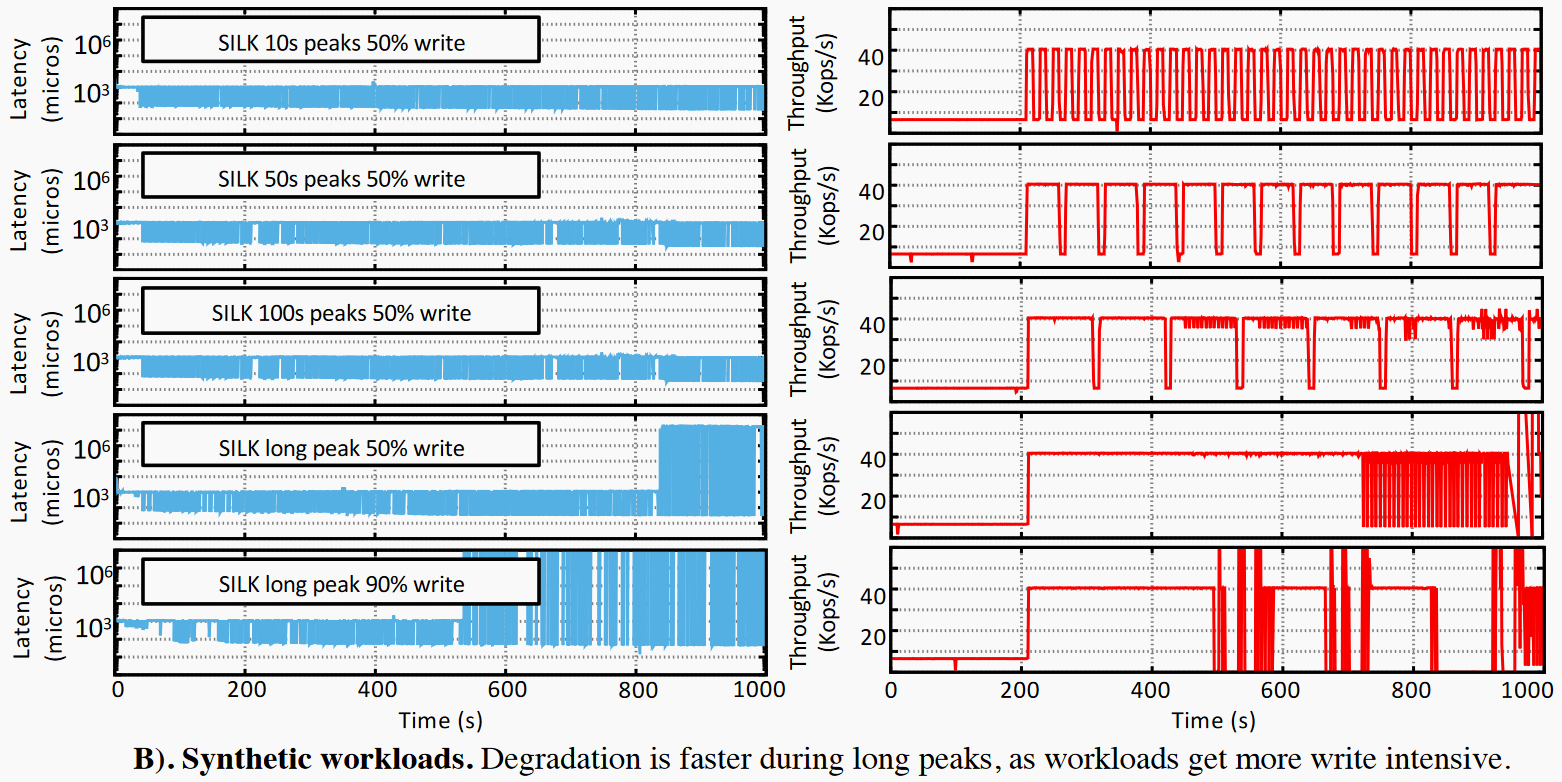
压力测试表明对于较短的负载尖峰和写操作占比,SILK对尾延迟的优化效果较好,当负载尖峰持续时间增加,写操作比例增加,系统无法为内部操作分配足够的资源,系统性能最终下降。并且写操作的占比也会影响尖峰持续的时间。
Breakdown
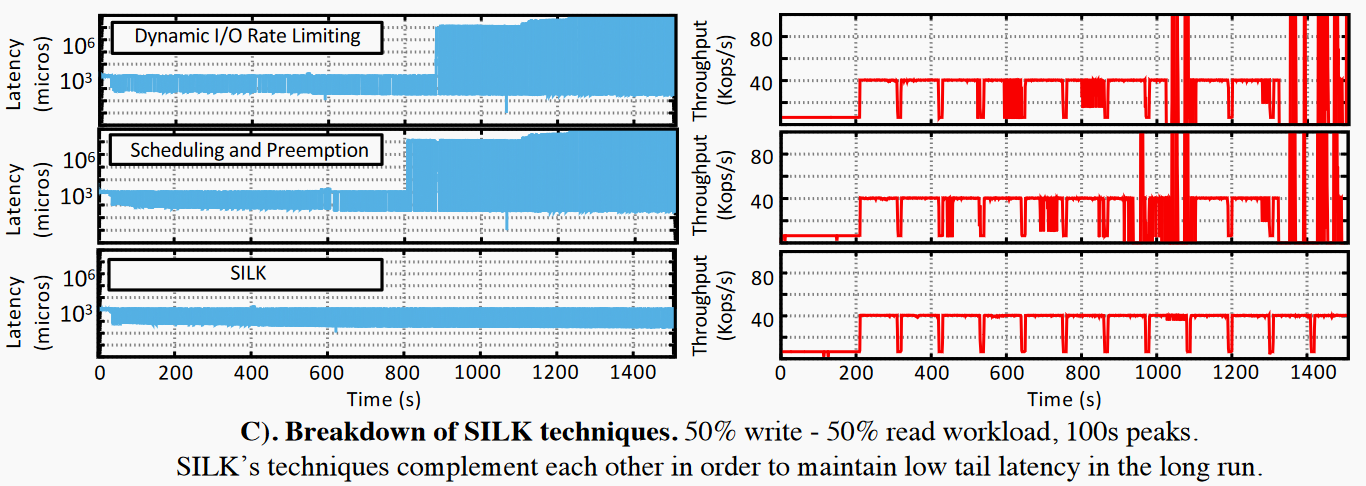
上图展示了SILK使用不同策略下99th延迟和吞吐变化。第一行SILK只使用了动态IO分配,第二行SILK只使用了优先级和抢占,第三行SILK综合了以上两种策略。两种策略单独使用都不能较好的解决尾延迟问题且不能长时间维持用户负载。
Conclusion
其他不说这篇文章的写作思路很清晰,基本思路就是通过动态分配IO带宽和优先级抢占来保证flush和L0合并操作能够及时处理。疑问点总结如下:
- rate limiter具体工作原理,文中提到了改动rate limiter有开销,所以设置了一个带宽变化的阈值;
- SILK在内存中实现了两个组件一个mutable一个immutable一个flush线程,也提到了更多组件和flush线程可能提升性能,为什么没有去做?有新的困难吗?
- 在compaction优先级抢占中,SILK会随机挑选一个被抢占的compaction线程,有没有更好的方式比如抢占更不“紧迫”的compaction线程;
- 被抢占的线程已做的工作不会被保存,会被直接丢弃,可以再优化吗?保存一些工作量;
- 在分配带宽的时候粒度可以更细吗?比如根据compaction任务的紧迫程度分配带宽;
 微信
微信 支付宝
支付宝


